
前回で学習済みのAIを使ってみて、前々回で、自分のデータを学習するための準備をしました。
-

-
参考【python AI】pytorch SSD 学習済みのAIを使って物体検知をする
続きを見る
-

-
参考【python AI】物体検出の実装方法 -データの準備-
続きを見る
データの準備ができたので、次は用意したデータを学習します。
学習するAIモデルにはSSDを使います。

動かすのに必要コードのみ知りたい
本記事の内容
- 事前準備
- 学習
- 学習したモデルを使って検知
今回は、3回に分けて、この技術の使い方を紹介してます。
3ステップ
- 学習済みAIを使ってみる
- データの準備
- AIを学習 👈 本記事はここ
今回は、3つ目の「AIを学習」になります。
ここでは、前回準備した犬の位置を検出できるように学習します。
下記リンクに、Jupyter Notebookとデータをセットでおいてあるので、参考にしてください。
目次
事前準備
始める前にいくつか準備いただくことがあるので、紹介していきます。
ライブラリのインストール
いくつか必要なライブラリがあります。
Google Colaboratoryを使う場合は、インストール済みですのでスキップしてください。
必要なライブラリ
- numpy
- tqdm
- matplotlib
- scikit-learn
- pytorch
pytorchのインストールは、下記pytorch公式のサイトを参照してください。
OSなどを選ぶとpipのコマンドなどが出てきます。
そのコマンドを使ってインストールしましょう。
SSDモデルのダウンロード
SSDのモデルをダウンロードします。
GitHubにあるpytorchのSSDのコードは、下記のものがあります。
ですが、今回はこちらを使わず、このコードをベースに日本語の書籍で紹介されているコードがありますので、そちらを使います。
下記の書籍で、コードの説明などがされていますので、購入するのもありです。
分かりやすく実践的な書籍です。
pytorch_advancedのGitHubからクローンのZipファイルをダウンロードしてください。
「2_objectdetection」フォルダにある「utils」を使います。
学習済みVGG16の取得
次に下記リンクより学習ずみのVGG16をダウンロードします。
ダウンロードした「vgg16_reducedfc.pth」を保存しておきます。
VGG16は画像分類でも使うAIモデルです。
なぜこれが必要か?
SSDのモデルの前の方では、VGG16を使っています。
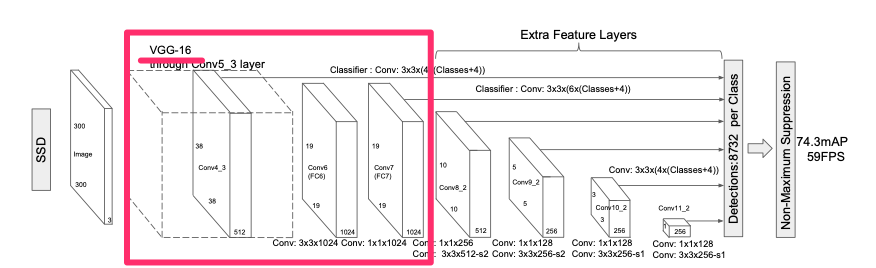
この部分を、すでに何かで学習したものを使うことができます。
今回は犬を検知したいタスクですが、事前に学習されたVGGに犬が含まれていなくても問題ありません。
この方法を転移学習と言います。
転移学習を使えば、少ないデータでも精度を出すことができます。
今回は140ほどのデータ学習させていますので、この方法は必須です。
フォルダ構成
さて、ここまで「utils」というフォルダと「vgg16_reducedfc.pth」というファイルを用意しました。
最終的には次のようなフォルダ構成にしましょう。

画像データ:od_dogsというフォルダに入れています。アノテーションのxmlも一緒です
utils:先程GitHubから取得したものそのままです
weights:weightsフォルダを作って、vgg16_reducedfc.pthを入れておきましょう
od_train.ipynbは今からコードを記載するjupyter notebookになります。
学習
今から、コードを使って、学習していきますが、次のステップになります。
学習までの流れ
- ライブラリ読み込み
- データ準備
- モデルの準備
- ロス、最適化関数の準備
- 学習
学習にはGPUが乗ったパソコンが必要になります。
GoogleColablatoryを使うと無料でGPUが使えます。
使い方は、Jupyter Labと似ています。
ライブラリ読み込み
まず、必要なライブラリを読み込みます。
# パッケージのimport import os.path as osp import os import sys import random import time import glob import cv2 import numpy as np from tqdm import tqdm import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split import torch import torch.nn as nn import torch.nn.init as init import torch.optim as optim import torch.utils.data as data from utils.ssd_model import VOCDataset, DataTransform, Anno_xml2list, od_collate_fn from utils.ssd_model import SSD from utils.ssd_model import MultiBoxLoss
from utils.ssd_modelとなっているところは、GitHubから拝借した、SSDのモデルとか必要な機能が入っています。
データ準備
pytorchではDataSet、DataLoderを使いますので、お作法にならって実装していきます。
# データのリストを取得
data_path = './od_dogs'
filename_list = [os.path.split(f)[1].split('.')[0] for f in glob.glob(f'{data_path}/*.xml')]
filename_list_train, filename_list_val = train_test_split(filename_list, test_size=0.1)
train_img_list = [f'{data_path}/{f}.jpg' for f in filename_list_train]
train_anno_list = [f'{data_path}/{f}.xml' for f in filename_list_train]
val_img_list = [f'{data_path}/{f}.jpg' for f in filename_list_val]
val_anno_list = [f'{data_path}/{f}.xml' for f in filename_list_val]
# Datasetを作成
voc_classes = ['dog']
color_mean = (104, 117, 123) # (BGR)の色の平均値
input_size = 300 # 画像のinputサイズ
train_dataset = VOCDataset(train_img_list,
train_anno_list,
phase="train",
transform=DataTransform(input_size, color_mean),
transform_anno=Anno_xml2list(voc_classes))
val_dataset = VOCDataset(val_img_list,
val_anno_list,
phase="val",
transform=DataTransform(input_size, color_mean),
transform_anno=Anno_xml2list(voc_classes))
# DataLoaderを作成する
train_dataloader = data.DataLoader(train_dataset,
batch_size=32,
shuffle=True,
collate_fn=od_collate_fn)
val_dataloader = data.DataLoader(val_dataset,
batch_size=3,
shuffle=False,
collate_fn=od_collate_fn)
# 辞書オブジェクトにまとめる
dataloaders_dict = {"train": train_dataloader, "val": val_dataloader}
自分のデータを用意された方は、vol_classesの検知したいリストを修正してください。
今回は、犬の検知をしたいだけなので、['dog']としています。
DataSetはデータの元を管理しつつ、データの変換などをします。
DataLoaderはDatasetのデータを順番に取得します
DataSetは画像の変換などをするので、AIモデルによって自分で用意することが多いですが、今回はすでにSSD用にVOCDataSetが用意されていますので、それを使っています。
モデルの準備
AIモデルを準備します。
まず、AIモデルを読み込みます。
# SSD300の設定
ssd_cfg = {
'num_classes': 2, # 背景クラスを含めた合計クラス数
'input_size': 300, # 画像の入力サイズ
'bbox_aspect_num': [4, 6, 6, 6, 4, 4], # 出力するDBoxのアスペクト比の種類
'feature_maps': [38, 19, 10, 5, 3, 1], # 各sourceの画像サイズ
'steps': [8, 16, 32, 64, 100, 300], # DBOXの大きさを決める
'min_sizes': [21, 45, 99, 153, 207, 261], # DBOXの大きさを決める
'max_sizes': [45, 99, 153, 207, 261, 315], # DBOXの大きさを決める
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
}
# SSDネットワークモデル
net = SSD(phase="train", cfg=ssd_cfg)
SSDの引数は2つphaseとcfgです。
phaseは学習時はtrainとし、cfgには、設定情報が入っているssd_cfgを入れます。
ssd_cfgの変更点はnum_classesのみで、今回は犬のみの検知なので1クラスですが、背景クラスというのがあって、+1します。
なので、num_classesは2が入っています。
次に、先程ダウンロードした学習済みVGG16を読み込みます。
# SSDの初期の重みを設定
vgg_weights = torch.load('./weights/vgg16_reducedfc.pth')
net.vgg.load_state_dict(vgg_weights)
VGG16の設定ができたら、その他の箇所は初期化してしまいます。
# ssdのその他のネットワークの重みはHeの初期値で初期化
def weights_init(m):
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight.data)
if m.bias is not None: # バイアス項がある場合
nn.init.constant_(m.bias, 0.0)
# Heの初期値を適用
net.extras.apply(weights_init)
net.loc.apply(weights_init)
net.conf.apply(weights_init)
# GPUが使えるかを確認
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("使用デバイス:", device)
print('ネットワーク設定完了:学習済みの重みをロードしました')
これでAIモデルの重みと呼ばれるものが設定できました。
重みは学習時にうまく検知できるように、調整されるパラメータのことです。
重みの初期化とついでに、GPUかCPUどちらが使えるかをdeviceに文字列入れています。
CPUマシーンの場合は、相当時間がかかります。
ロス、最適化関数の準備
ロスと最適化関数を設定します。
# 損失関数の設定 criterion = MultiBoxLoss(jaccard_thresh=0.5, neg_pos=3, device=device) # 最適化手法の設定 optimizer = optim.SGD(net.parameters(), lr=1e-3, momentum=0.9, weight_decay=5e-4)
ロス(損失関数)はアノテーションしたデータとAIが検知(推論)した結果の違いを値にしたもの。
ロスが小さくなれば、AIの精度が上がっている状態です。
最適化関数は算出されたロスを元に、ロスを小さくするためのアルゴリズムです。
ここら辺をまだ知らない方は、線型回帰の機械学習について調べてみましょう。
基本的な考えを知ることができます。
学習
最後に学習になります。
学習用の関数を用意して、動かします。
学習用の関数は次のようになります。
# モデルを学習させる関数を作成
def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs):
# GPUが使えるかを確認
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("使用デバイス:", device)
# ネットワークをGPUへ
net.to(device)
# ネットワークがある程度固定であれば、高速化させる
torch.backends.cudnn.benchmark = True
# イテレーションカウンタをセット
iteration = 1
epoch_train_loss = 0.0 # epochの損失和
epoch_val_loss = 0.0 # epochの損失和
min_loss = 9999
logs = []
# epochのループ
for epoch in range(num_epochs+1):
# 開始時刻を保存
t_epoch_start = time.time()
t_iter_start = time.time()
# epochごとの訓練と検証のループ
for phase in ['train', 'val']:
if phase == 'train':
net.train()
else:
net.eval()
# データローダーからminibatchずつ取り出すループ
with tqdm(dataloaders_dict[phase], desc=phase, file=sys.stdout) as iterator:
for images, targets in iterator:
# GPUが使えるならGPUにデータを送る
images = images.to(device)
targets = [ann.to(device)
for ann in targets] # リストの各要素のテンソルをGPUへ
# optimizerを初期化
optimizer.zero_grad()
# 順伝搬(forward)計算
with torch.set_grad_enabled(phase == 'train'):
# 順伝搬(forward)計算
outputs = net(images)
# 損失の計算
loss_l, loss_c = criterion(outputs, targets)
loss = loss_l + loss_c
# 訓練時はバックプロパゲーション
if phase == 'train':
loss.backward()
nn.utils.clip_grad_value_(net.parameters(), clip_value=2.0)
optimizer.step()
epoch_train_loss += loss.item()
iteration += 1
# 検証時
else:
epoch_val_loss += loss.item()
# epochのphaseごとのlossと正解率
t_epoch_finish = time.time()
print(f'epoch {epoch+1}/{num_epochs} {(t_epoch_finish - t_epoch_start):.4f}sec || train_Loss:{epoch_train_loss:.4f} val_Loss:{epoch_val_loss:.4f}')
t_epoch_start = time.time()
# vallossが小さい、ネットワークを保存する
if min_loss>epoch_val_loss:
min_loss=epoch_val_loss
torch.save(net.state_dict(), 'weights/ssd_best.pth')
epoch_train_loss = 0.0 # epochの損失和
epoch_val_loss = 0.0 # epochの損失和
この書き方もよく見られる書き方だと思います。
検証用のデータが小さい場合にweightsフォルダに「ssd_best.pth」で学習したモデルを保存しています。
では、実際に学習を実行してみましょう。
# 学習・検証を実行する num_epochs= 200 train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)
データ少ないので、エポック数200 で実行しています。

処理結果がログで出てきます。
train_loss, val_lossがどんどん下がっていきます。
Legacy...とエラーが出る場合
pytorchのバージョンのためか、エラーが出る場合は、次のようにコードを変更してください。
私は出てしまいました。
utilsフォルダのssd_model.pyを変更します。
1箇所目は633行目のDetectクラスです。

コードも添付しておきます。
class Detect(Function):
# def __init__(self, conf_thresh=0.01, top_k=200, nms_thresh=0.45):
# self.softmax = nn.Softmax(dim=-1) # confをソフトマックス関数で正規化するために用意
# self.conf_thresh = conf_thresh # confがconf_thresh=0.01より高いDBoxのみを扱う
# self.top_k = top_k # nm_supressionでconfの高いtop_k個を計算に使用する, top_k = 200
# self.nms_thresh = nms_thresh # nm_supressionでIOUがnms_thresh=0.45より大きいと、同一物体へのBBoxとみなす
@staticmethod
def forward(self, loc_data, conf_data, dbox_list):
"""
順伝搬の計算を実行する。
Parameters
----------
loc_data: [batch_num,8732,4]
オフセット情報。
conf_data: [batch_num, 8732,num_classes]
検出の確信度。
dbox_list: [8732,4]
DBoxの情報
Returns
-------
output : torch.Size([batch_num, 21, 200, 5])
(batch_num、クラス、confのtop200、BBoxの情報)
"""
self.conf_thresh = 0.01 # confがconf_thresh=0.01より高いDBoxのみを扱う
self.top_k = 200 # nm_supressionでconfの高いtop_k個を計算に使用する, top_k = 200
self.nms_thresh = 0.45 # nm_supressionでIOUがnms_thresh=0.45より大きいと、同一物体へのBBoxとみなす
# 各サイズを取得
num_batch = loc_data.size(0) # ミニバッチのサイズ
num_dbox = loc_data.size(1) # DBoxの数 = 8732
num_classes = conf_data.size(2) # クラス数 = 21
# confはソフトマックスを適用して正規化する
conf_data = F.softmax(conf_data, dim=-1) # change
# 出力の型を作成する。テンソルサイズは[minibatch数, 21, 200, 5]
output = torch.zeros(num_batch, num_classes, self.top_k, 5)
# cof_dataを[batch_num,8732,num_classes]から[batch_num, num_classes,8732]に順番変更
conf_preds = conf_data.transpose(2, 1)
もう1箇所は、SSDクラスの下の方で809行目のところです。

コードも添付します。
if self.phase == "inference": # 推論時
# クラス「Detect」のforwardを実行
# 返り値のサイズは torch.Size([batch_num, 21, 200, 5])
return self.detect.apply(output[0], output[1], output[2]) # change
else: # 学習時
return output
# 返り値は(loc, conf, dbox_list)のタプル
この2箇所を変更すれば、エラーが解消されます
学習したモデルで検知
学習したモデルを実際に使って、アプリケーションなどに実装する場合の紹介をします。
やることは次の3つです。
コード実装の3ステップ
- ライブラリ読み込み
- SSDモデル設定
- 新しい画像で検知
ライブラリ読み込み
必要なライブラリを読み込みます。
from utils.ssd_model import SSD from utils.ssd_model import DataTransform import cv2 # OpenCVライブラリ import matplotlib.pyplot as plt import numpy as np import torch from utils.ssd_predict_show import SSDPredictShow
SSDモデル設定
SSDモデルを設定します。
学習時とほぼ同じですが、SSDのphase='inference'のところと、学習済みのssd_best.pthを読み込んでいる点が違います。
voc_classes = ['dog']
# SSDネットワークモデル
ssd_cfg = {
'num_classes': 2, # 背景クラスを含めた合計クラス数
'input_size': 300, # 画像の入力サイズ
'bbox_aspect_num': [4, 6, 6, 6, 4, 4], # 出力するDBoxのアスペクト比の種類
'feature_maps': [38, 19, 10, 5, 3, 1], # 各sourceの画像サイズ
'steps': [8, 16, 32, 64, 100, 300], # DBOXの大きさを決める
'min_sizes': [21, 45, 99, 153, 207, 261], # DBOXの大きさを決める
'max_sizes': [45, 99, 153, 207, 261, 315], # DBOXの大きさを決める
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
}
net = SSD(phase="inference", cfg=ssd_cfg)
# SSDの学習済みの重みを設定
net_weights = torch.load('./weights/ssd_best.pth', map_location={'cuda:0': 'cpu'})
net.load_state_dict(net_weights)
print('ネットワーク設定完了:学習済みの重みをロードしました')
新しい画像で検知
では、適当な犬の画像を使って、検知できるか見ていきます。
jupyter notebookと同じフォルダに、dog_test.jpgを置いて、検知してみます。
# ファイルパス
image_file_path = "./dog_test.jpg"
# 予測と、予測結果を画像で描画する
ssd = SSDPredictShow(eval_categories=voc_classes, net=net)
ssd.show(image_file_path, data_confidence_level=0.5)
# ボックスなどを取得
rgb_img, predict_bbox, pre_dict_label_index, scores = ssd.ssd_predict(image_file_path)
for i in range(len(predict_bbox)):
print('box', predict_bbox[i])
print('label', voc_classes[pre_dict_label_index[i]])
print('score', scores[i])
最初に、ssd.showで検知した結果を表示します。
次に、ssd.ssd_predictで実際の検知したものを四角のボックスや確信度も表示しています。

分かりやすい犬のデータばかり使っているというのもありますが、約140のデータにしては、ちゃんと検知できています。
この一連の流れで、数千枚の画像をしっかり学習すれば、自分の使いたい物体検知のAIが開発できるようになります。