
前回セグメンテーション用のデータを準備しました。
-

-
参考【python AI】セマンティックセグメンテーションの実装方法 -データの準備-
続きを見る
次はこのデータを使って学習をして、画像に映った犬と背景を分けれるようにします。
本記事はこんな方におすすめです。

どのライブラリを使えばわからない
本記事の内容
- セグメンテーションできるライブラリ
- 学習の実装
- 学習後の確認方法
目次
ライブラリ
ライブラリは以下のものを使用します。
| AI | pytorch |
| セグメンテーション | segmentation-models-pytorch |
| データ拡張 | albumentations |
| 画像 | opencv-python |
| 画像表示 | matplotlib |
AIライブラリのpytorchは下記リンクを参照して、OSなどを選択してインストールしてください。
次のようにOSやCUDAのバージョンを選択して、出てくるpip コマンドを使います。

セグメンテーション用のモデルは下記のGitHubのものを使わせていただきます。
セグメンテーションのモデルを構成する、エンコーダー、デコーダーのモデルが色々組み合わせて選ぶことができて、使い方も比較的簡単です。
>> segmentation-models-pytorch (GitHub)
学習にはGPUがのったパソコンが必要になります。
手元に無い方は、Google Colaboratoryを利用してください。
その場合のライブラリのインストールはセルでpipを実行します。
次のように!をつけるとインストールができます。
学習の実装
前回の「【python AI】セマンティックセグメンテーションの実装方法 -データの準備-」で準備したデータを使って、学習をしていきます。
-
-
参考【python AI】セマンティックセグメンテーションの実装方法 -データの準備-
続きを見る
コード全体は少し長くなるので、下記のGitHubを参照ください。
上記コードを小分けにして紹介していきますが、ライブラリで紹介されているコードを参考にさせていただいています。
>> segmentation-models-pytorch のサンプルコード
ライブラリ読み込み
まず、必要なライブラリを読み込みます。
# ライブラリ読み込み import glob import cv2 import numpy as np import os from torch.utils.data import DataLoader from torch.utils.data import Dataset as BaseDataset import torch import torch.nn as nn import torch.nn.functional as F import segmentation_models_pytorch as smp import albumentations as albu import matplotlib.pyplot as plt
関数の宣言
いくつか関数を宣言します。
データセットの確認
データセットの中身を確認するための関数です
# データ確認用
def visualize(**images):
"""PLot images in one row."""
n = len(images)
plt.figure(figsize=(16, 5))
for i, (name, image) in enumerate(images.items()):
plt.subplot(1, n, i + 1)
plt.xticks([])
plt.yticks([])
plt.title(' '.join(name.split('_')).title())
plt.imshow(image)
plt.show()
データ拡張
データが少ない場合、データをずらしたり反転したりすることで、データの量を増やしますが、その処理関数になります。
# データ拡張
def get_training_augmentation():
IMAGE_SIZE = 256
train_transform = [
albu.HorizontalFlip(p=0.5),
albu.ShiftScaleRotate(scale_limit=0.5, rotate_limit=0, shift_limit=0.1, p=1, border_mode=0),
albu.PadIfNeeded(min_height=IMAGE_SIZE, min_width=IMAGE_SIZE, always_apply=True, border_mode=0),
albu.RandomCrop(height=IMAGE_SIZE, width=IMAGE_SIZE, always_apply=True),
albu.IAAAdditiveGaussianNoise(p=0.2),
albu.IAAPerspective(p=0.5),
albu.OneOf(
[
albu.CLAHE(p=1),
albu.RandomBrightness(p=1),
albu.RandomGamma(p=1),
],
p=0.9,
),
albu.OneOf(
[
albu.IAASharpen(p=1),
albu.Blur(blur_limit=3, p=1),
albu.MotionBlur(blur_limit=3, p=1),
],
p=0.9,
),
albu.OneOf(
[
albu.RandomContrast(p=1),
albu.HueSaturationValue(p=1),
],
p=0.9,
),
]
return albu.Compose(train_transform)
データ の前処理
imagenetの学習済みモデルを部分的に使うので、その正規化処理や、画像の「高さ,幅,CH」を「CH,高さ,幅」の入れ替えを行なっています。
# テンソル化
def to_tensor(x, **kwargs):
return x.transpose(2, 0, 1).astype('float32')
# 前処理
def get_preprocessing(preprocessing_fn):
_transform = [
albu.Lambda(image=preprocessing_fn),
albu.Lambda(image=to_tensor, mask=to_tensor),
]
return albu.Compose(_transform)
データセット
関数ではありませんが、BaseDatasetを継承して、Datasetを作ります。
# データセット
class Dataset(BaseDataset):
CLASSES = ['background', 'dog']
def __init__(
self,
images_dir,
masks_dir,
classes=None,
augmentation=None,
preprocessing=None,
):
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
# convert str names to class values on masks
self.class_values = [classes.index(cls.lower()) for cls in classes]
self.augmentation = augmentation
self.preprocessing = preprocessing
def __getitem__(self, i):
# read data
image = cv2.imread(self.images_fps[i])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# mask
mask = cv2.imread(self.masks_fps[i], 0)
masks = [(mask == v) for v in self.class_values]
mask = np.stack(masks, axis=-1).astype('float')
# apply augmentations
if self.augmentation:
sample = self.augmentation(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
# apply preprocessing
if self.preprocessing:
sample = self.preprocessing(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
return image, mask
def __len__(self):
return len(self.ids)
モデルを宣言
モデルを決めます。
今回はエンコーダーにresnet34、デコーダーにUNetを選んでいます。
色々な組み合わせが、ありますので、精度が良くなるように色々試してみると良いでしょう。
# モデルを宣言
ENCODER = 'resnet34'
ENCODER_WEIGHTS = 'imagenet'
CLASSES = ['dog']
ACTIVATION = 'sigmoid' # could be None for logits or 'softmax2d' for multicalss segmentation
DEVICE = 'cuda'
DECODER = 'unet'
model = smp.Unet(
encoder_name=ENCODER,
encoder_weights=ENCODER_WEIGHTS,
classes=len(CLASSES),
activation=ACTIVATION,
)
model = model.to("cuda")
データセットを作成
データセットを作成します。
前回作った、データはtrain、valフォルダに分けましたので、それを読み込みます。
train_dir = 'train'
val_dir = 'val'
preprocessing_fn = smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)
# データセットを作成
train_dataset = Dataset(
os.path.join(train_dir, 'images'),
os.path.join(train_dir, 'masks'),
augmentation=get_training_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=['dog'],
)
valid_dataset = Dataset(
os.path.join(val_dir, 'images'),
os.path.join(val_dir, 'masks'),
preprocessing=get_preprocessing(preprocessing_fn),
classes=['dog'],
)
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True, num_workers=0)
valid_loader = DataLoader(valid_dataset, batch_size=1, shuffle=False, num_workers=0)
データを確認してみます。
# データ確認
dataset = Dataset(os.path.join(train_dir, 'images'), os.path.join(train_dir, 'masks'), classes=['dog'])
image, mask = dataset[5] # get some sample
visualize(
image=image,
dog_mask=mask.squeeze(),
)

ちゃんと読み込めていることが確認できます。
学習
データが読めたので、学習に進みます。
学習の精度指標やloss、最適化関数を決めます。
# 精度確認指標
metrics = [
smp.utils.metrics.IoU(threshold=0.5),
]
# ロス
loss = smp.utils.losses.DiceLoss()
# 最適化関数
optimizer = torch.optim.Adam([
dict(params=model.parameters(), lr=0.001),
])
最適化関数など変更できる方は、色々試してみると良いでしょう。
精度指標は、IoUという指標ですが、下記リンクがとてもわかりやすく紹介されています。
ライブラリに、1エポック学習するものが用意されているので、それを使います。
# 1Epochトレイン用
train_epoch = smp.utils.train.TrainEpoch(
model,
loss=loss,
metrics=metrics,
optimizer=optimizer,
device=DEVICE,
verbose=True,
)
valid_epoch = smp.utils.train.ValidEpoch(
model,
loss=loss,
metrics=metrics,
device=DEVICE,
verbose=True,
)
あとは、決めた回数分学習しますが、今回は40とします。
25Epoch目に学習率を変更しています。
# 学習 40EPoch 25Epochで学習率を下げる
max_score = 0
for i in range(0, 40):
print('\nEpoch: {}'.format(i))
try:
train_logs = train_epoch.run(train_loader)
val_logs = valid_epoch.run(valid_loader)
except Exception as e:
print(e)
# do something (save model, change lr, etc.)
if max_score < val_logs['iou_score']:
max_score = val_logs['iou_score']
torch.save(model, f'{DECODER}_{ENCODER}.pth')
print('Model saved!')
if i == 25:
optimizer.param_groups[0]['lr'] = 1e-4
print('Decrease decoder learning rate to 1e-4!')
こんな感じで学習が完了します。

学習後の確認
学習したモデルを使って、どのようにセグメンテーションできるか確認します。
テスト用の画像を用意せず、そのままvalフォルダのデータを使っていきます。
# 画像読み込み
val_files = glob.glob('val/images/*')
f = val_files[5]
image_src = cv2.imread(f)
image_src = cv2.cvtColor(image_src, cv2.COLOR_BGR2RGB)
# 前処理
image = preprocessing_fn(image_src)
image = image.transpose(2, 0, 1).astype('float32')
# モデルで推論
image=torch.from_numpy(image).to(DEVICE).unsqueeze(0)
predict = model(image)
predict = predict.detach().cpu().numpy()[0].reshape((256,256))
# 0.5以上を1とする
predict_img = np.zeros([256,256]).astype(np.int8)
predict_img = np.where(predict>0 .5, 1 , predict_img)
これで、AIが予測して結果が取得できたので、表示してみます。
# 横並び fig = plt.figure(figsize=(12, 6)) ax1 = fig.add_subplot(1, 2, 1) ax2 = fig.add_subplot(1, 2, 2) ax1.imshow(image_src) ax2.imshow(predict_img)
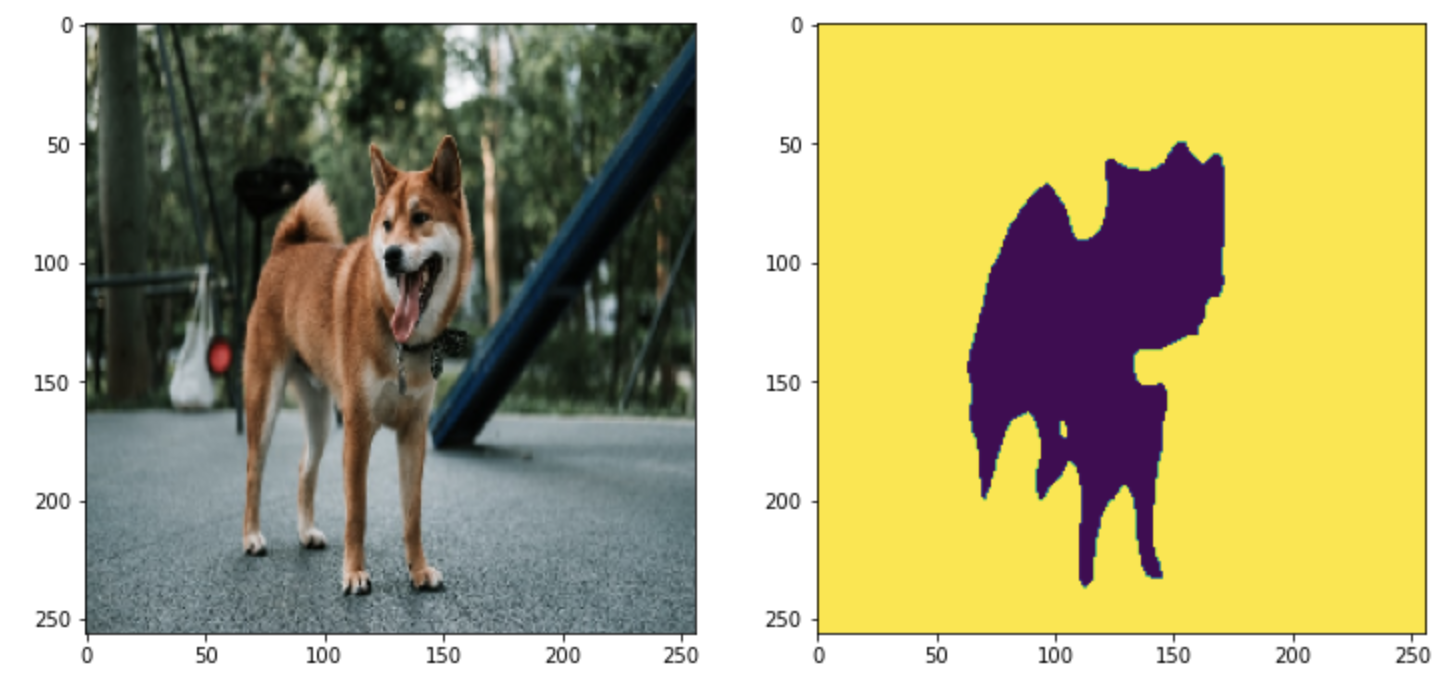
精度がいいとは言えませんね。
100枚の学習なので仕方がありませんが、AIモデルのエンコーダー、デコーダなど調整して色々試すとまた違った結果になりますので、色々試してみてください。