
AIには、セマンティックセグメンテーションという技術があります。
下記のような、物の種類を色分け(クラス分け)する技術です。

>> Rethinking Atrous Convolution for Semantic Image Segmentation
AIを始めた方でもみたことあるのではないでしょうか?
本記事はこんな方におすすめです。

データの準備(アノテーション)はどうすれば良いの
本記事の内容
- 準備するデータについて
- アノテーションツール
- アノテーションデータの変換
今回は、2回に分けて、この技術の使い方を次の2ステップで紹介していきます。
2ステップ
- データの準備
- AIを学習
今回は、1つ目のデータの準備です。
犬の画像を適当に100枚ほど集めて、その画像を使って、学習用の画像を作っていきます。
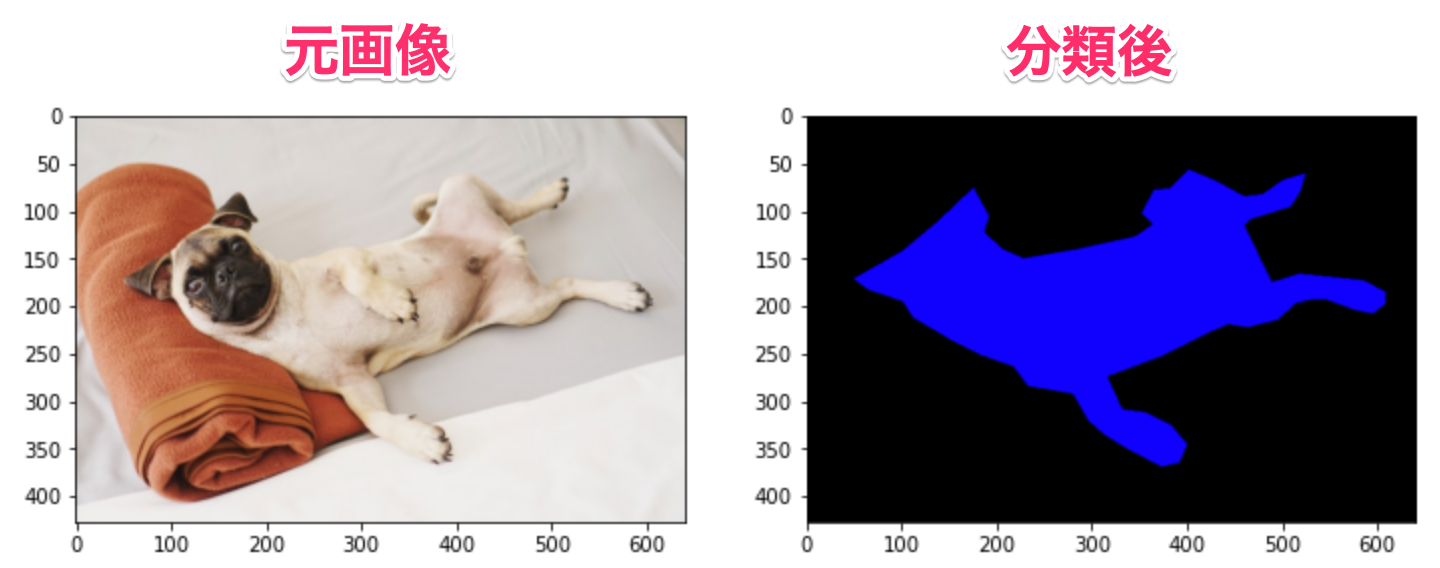
以下のように、左の画像と右の画像を用意していきます。
目次
準備するデータについて
準備するデータは、集めた画像と分類後の画像の二つです。
この分類後の画像はピクセル単位で分類されているものになります。
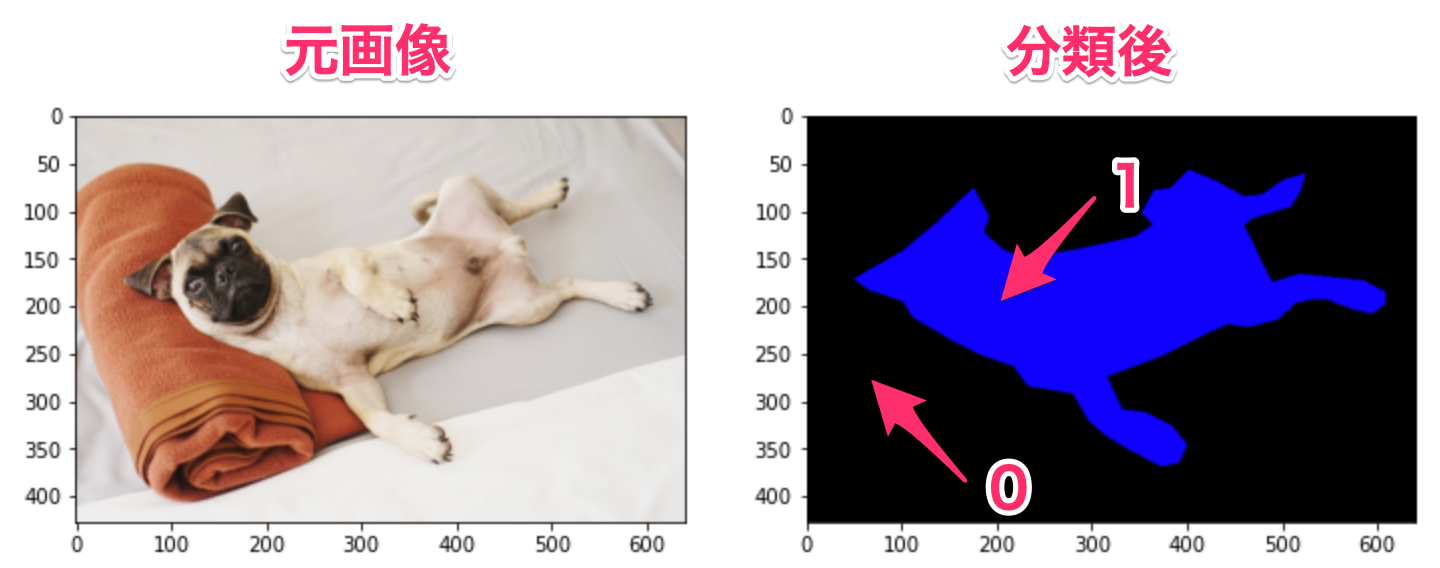
例えば、右の画像のように0が背景、1が犬というように分類ごとに数値で分けます。
画像はピクセルごとに、0-255の数値を持つことができるので、255種類までいけます。
仮に、255種類超える場合でも、特に画像でデータ保存せずに配列データをそのまま保存しても良いです。
右図は、英語ではGround Truthと呼ばれています。
アノテーションツール
画像をピクセル単位でクラス分けする必要があります。
方法としては、ペイントツールで、赤色、青色などをペンタブ使って色を塗るという方法でも良いのですが、手間がかかりすぎるので以下のツールを使っていきます。
似たようなツールに、labelImgというものもありますが、別のものになります。
ちなみに、アノテーションはAIに教え込ませるためのデータを作る作業のことです。
今回だと、ピクセルごとに犬と背景に分かれたデータを作る作業です。
インストール方法
インストールはGithubで紹介されています。
Anacondaなどでpython環境を用意して、pip install labelmeとするだけです。
今回は、Windowsのみになりますが、下記記事で紹介しているpython embeddableを使ってインストールしてみます。
*python環境はなんでも良いですが、わからない方は参考にしてください。
-

-
参考Windowsでpythonを使う/配布する時に便利!Python embeddable package使い方
続きを見る
次のサンプルコードをGitからダウンロードします。
ダウンロードしたら、フォルダ名は適当にlabelmeなどに変更してください。
python_console.batを起動します。
起動したら、python -m pip install labelmeを入力します。
次に、labelmeと入力すると起動します。
起動すると次の画面が立ち上がります。
アノテーションの方法
事前に、犬のフリー素材を114つ集めましたので、そのデータを使っていきます。
Githubに置いてありますので、参考にしてください。
seg_dogsというフォルダに入っています。
「OpenDir」でseg_dogsフォルダを選んでください。
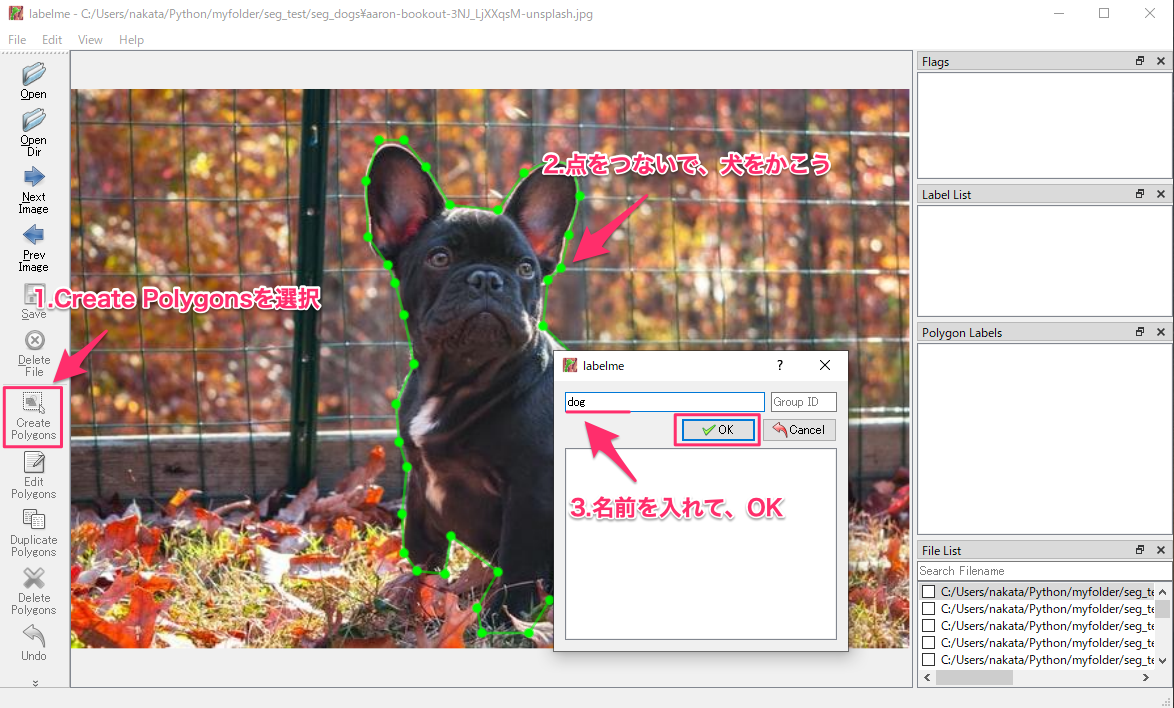
次は、CreatePolygonsを押して、犬を点で囲っていきます。
開始位置に戻ると、名前を入力してとなるので、適当に「dog」とします。
アノテーションしたデータは「Save」を押して、保存します。
画像と同じフォルダに、json形式のデータで保存されます。
ポイント
犬の毛並みがふわふわして境界線が引きずらい場合は、ご自身の感覚で
犬の手前に物がある場合、ポリゴンを二つに分ける
犬が2匹以上いる場合、ボリゴンを複数に分ける
あとは、NextImageを押して、集めた画像を全て、アノテーションして保存していきます。
メニューのFileから「Save Automatically」を選択しておくと、Saveを押さなくても保存してくれます。
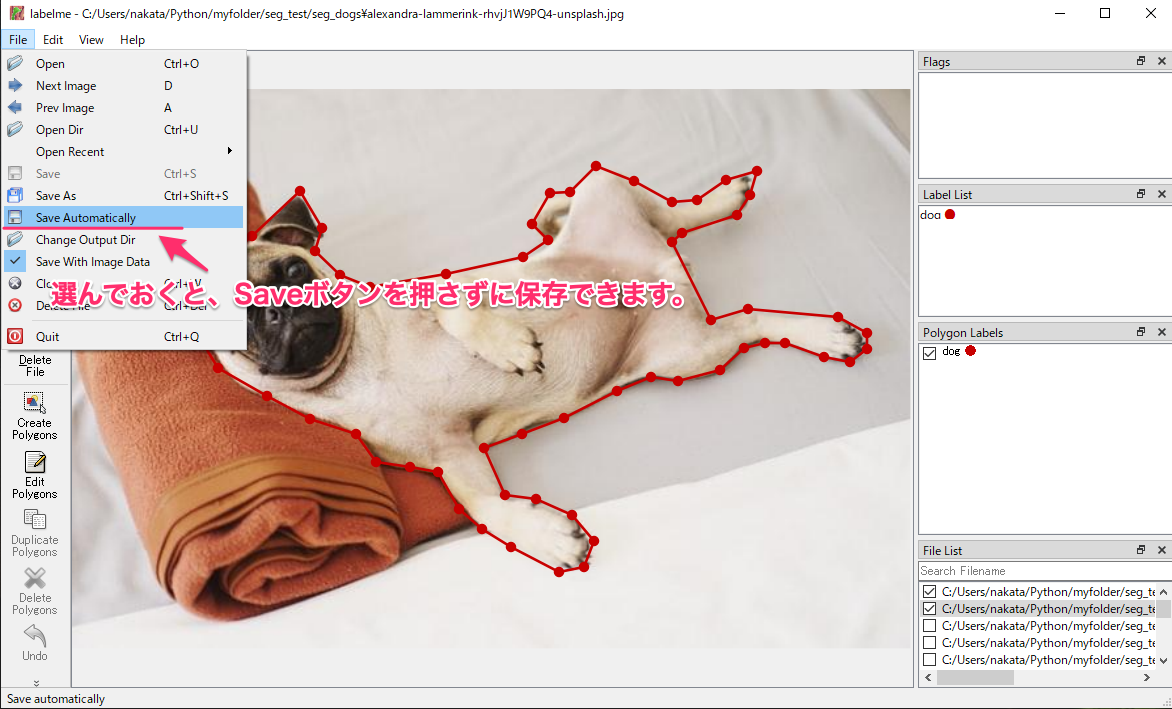
全部のデータのアノテーションが終わると、同じフォルダにJSONファイルがたくさんできています。
このファイルを使って、実際に学習するデータを作っていきます。
アノテーションデータの変換
時間をかけてアノテーションをしましたが、そのままでは学習データとして使えません。
右の画像のように、0と1の画像を用意する必要があります。
犬だけでなく、複数分類する場合は、1,2,3と数字が分類したい分、増えていきます。
変換する全体のコードは下記のGithubにおいてあるので、参考にしてください。
このnotebookのコードを順番に紹介していきます。
ライブラリ読み込み
まず必要なライブラリを読み込みます。
OS、画像、画像表示用のライブラリになります。
不足しているものはインストールしてください。
import json import os import glob import shutil # 画像関係 import numpy as np import cv2 from PIL import Image # 画像表示 import matplotlib.pyplot as plt IMAGE_SIZE = 256
学習用は256×256で保存するので、そのサイズも定義してあります。
データ読み込みと確認
アノテーションによって、できたjsonファイルを確認します。
ファイルのリストを取得します。
# データのリスト
json_list = glob.glob('seg_dogs/*.json')
img_list = [f.replace('json', 'jpg') for f in json_list]
print(len(json_list))
114個のリストが取得できます。
データを1つ読み込みます。
no = 1
# アノテーションデータ読み込み
with open(json_list[no]) as f:
data = json.loads(f.read())
# 1つだけ取り出す
shape = data['shapes'][0]
label = shape['label']
points = shape['points']
shape_type = shape['shape_type']
print('[label]', label)
print('[shape_type]', shape_type)
print('[points]', points)
[label] dog [shape_type] polygon [points] [[100.76335877862596, 195.42748091603053], [64.8854961832061, 183.21374045801525], [49.61832061068702, 172.5267175572519], [100.0, 143.51908396946564], [137.40458015267174, 112.22137404580153], [174.04580152671755, 77.87022900763358], [190.83969465648855, 106.1145038167939], [185.49618320610685, 123.67175572519082], [204.5801526717557, 141.99236641221373], [227.48091603053433, 151.15267175572518], [285.4961832061069, 141.22900763358777], [344.2748091603053, 128.25190839694656], [363.3587786259542, 115.274
jsonの中身は、1つの画像ごとに、点で囲った分のshapeが入っています。
犬が2匹いれば、shapeが2つできるということです。
shapeの中身は、画像パスや画像データも含まれますが、使うのは次の3つです。
shapeで使うもの
label: 今回はdogですが、囲った領域につけたラベル名
shape_type: ポリゴン以外にもポイントや四角などがある
points: ポリゴンの各ポイント
labelは「dog」、shape_type は「polygon」とそれぞれ1つなので、実際に必要なのはpointsのみです。
データの変換
jsonファイルのポリゴンデータを使って、最終的にAIに出力させたい画像を作っていきます。
背景が0、犬が1となっている画像です。
# 画像読み込み img = cv2.imread(img_list[no]) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # アノテーション部分 mask = np.zeros((img.shape[0], img.shape[1]), dtype=np.uint8) mask = cv2.fillPoly(mask, np.int32([points]), 1) # 横並びに表示 fig = plt.figure(figsize=(12, 6)) ax1 = fig.add_subplot(1, 2, 1) ax2 = fig.add_subplot(1, 2, 2) ax1.imshow(img) ax2.imshow(mask, cmap='gray')
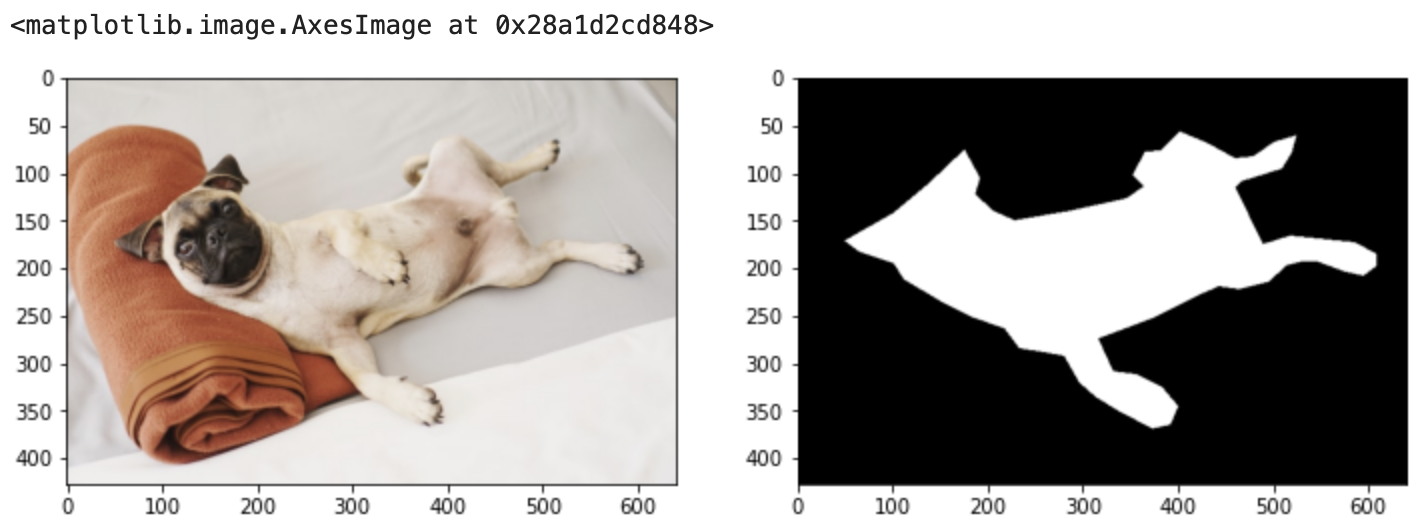
次のステップで処理しています。
ステップ
- 画像データを読み込む
- 画像の縦横のサイズを取得して、全て0の配列データ(画像)を作成
- cv2.fillPolyを使って、pointsのポリゴン箇所を0から1に変更
- 並べて表示
データをtrain/valに分けて保存
jsonファイルの変換がわかったので、あとは全データ保存します。
画像はtrainとvalにそれぞれ、100と14つずつ分けます。
画像は、256にリサイズして、pngで保存しています。
train、valフォルダを作成します。
それぞれに、imagesとmasksフォルダも作成。
jsonから作る画像はmasksに保存していきます。
# フォルダ作成 trainとvalにデータを分けます
train_dir = 'train'
val_dir = 'val'
if not os.path.exists(train_dir):
os.mkdir(train_dir)
os.mkdir(train_dir + '/images')
os.mkdir(train_dir + '/masks')
if not os.path.exists(val_dir):
os.mkdir(val_dir)
os.mkdir(val_dir + '/images')
os.mkdir(val_dir + '/masks')
ファイルリストを順番に読み込んで、保存していきます。
# 114個のデータを用意したので 100 と 14 に分けます
for ind, file in enumerate(json_list):
points = []
with open(file) as f:
data = json.loads(f.read())
for s in data['shapes']:
points.append(s['points'])
if points:
# 画像データを読み込み画像サイズ取得
img_path = file.replace('json', 'jpg')
img = cv2.imread(img_path)
# ファイル名
file_name = os.path.basename(img_path)
# jsonのアノテーションデータ
# 犬:1
# 背景:0
mask = np.zeros((img.shape[0], img.shape[1]), dtype=np.uint8)
for p in points:
mask = cv2.fillPoly(mask, np.int32([p]), 1)
# リサイズ
img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE), interpolation=cv2.INTER_NEAREST)
mask = cv2.resize(mask, (IMAGE_SIZE, IMAGE_SIZE), interpolation=cv2.INTER_NEAREST)
# 保存
file_name = file_name.replace('jpg', 'png')
if ind<100:
maskim = Image.fromarray(np.uint8(mask))
maskim.save(f'train/masks/{file_name}')
cv2.imwrite(f'train/images/{file_name}', img)
else:
maskim = Image.fromarray(np.uint8(mask))
maskim.save(f'val/masks/{file_name}')
cv2.imwrite(f'val/images/{file_name}', img)
これを実行したあと、train、valフォルダにデータが分かれて保存されます。
保存できたか確認してみましょう。
以上がデータの準備になります。
次は、実際に学習していきます。
-

-
参考【python AI】セマンティックセグメンテーションの実装方法 -学習と確認-
続きを見る