
pythonでは必須ライブラリのnumpyについて説明していきます。
numpyはデータ解析でも画像処理でも出てくるので、習得必須になります。
本記事はこんな方におすすめです。

本記事の内容
- numpyとは
- numpyの用途
- numpyの基本的な使い方
python入門 基礎まとめも参考にしてください。
目次
numpyとは
numpyは行列などの多次元の数値計算を効率的にできるライブラリです。
例えば、次のようなデータ1、2を掛け算、足し算や行列としての計算もできます。
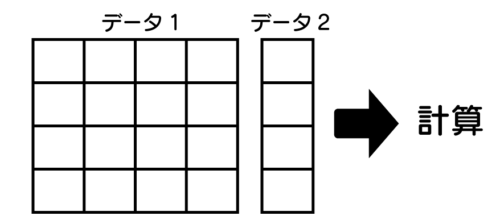
用途
多次元の計算ができるので、色々な使い方があります。
用途例
- データの計算、統計値計算
- データの異常度計算
- 画像処理
- 機械学習
計算処理は大抵numpyが考慮されているので、他のライブラリでの処理結果をnumpyを使って処理するということもよくあります。
基本的な使い方
numpyを読み込む
numpyの読み込みはほぼ固定です。
import numpy as np
npの部分を他に変更することもできますが、他の人が見た時にややこしいので、できる限り上記を使いましょう。
データを作る
numpyのデータを作っていきます。
numpyでデータを作る
0、1、乱数を作ってみます。
zerosメソッドで、0を作ります。今回は2次元の[5, 3] = 5×3のデータを作っています。
# 0のデータ data = np.zeros([5,3]) print(data)
[[0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.]]

onesメソッドで、1を作ります。
# 1のデータ data = np.ones([5,3]) print(data)
[[1. 1. 1.] [1. 1. 1.] [1. 1. 1.] [1. 1. 1.] [1. 1. 1.]]
random.randで、0-1の乱数を作成します。
# 乱数 data = np.random.rand(5,3) print(data)
[[0.78372933 0.51364056 0.96222633] [0.00278798 0.59879671 0.72964373] [0.32668617 0.90837737 0.7559846 ] [0.47016603 0.8837441 0.66019806] [0.30326067 0.59889198 0.38398319]]

乱数は他にもnp.randomモジュールの中に複数ありますが、今回は乱数が作れるという紹介にとどめておきます。
おまけに、データのサイズと型を確認してみます。
データのサイズを確認します。
# データの形はshapeで確認 print(data.shape)
(5, 3)
行数5、列数3なのがわかります。
データのサイズの確認はしょっちゅうしますので、ぜひ覚えておいてください。
次に型を確認します。
# 型はndarrayというのもになります。 print(type(data))
<class 'numpy.ndarray'>
ndarrayという型なのがわかります。
これは、こういう型だと確認しただけで、しょっちゅう確認することはありません。
list,tuple,dictからデータを作る
listから作る。np.array()の引数にlistを入れるだけです。
# listデータから
list_data = [[1,2,3],
[4,5,6],
[7,8,9]]
data = np.array(list_data)
print(data)
[[1 2 3] [4 5 6] [7 8 9]]
tupleでも作りますが、listと同じです。
# tupleデータから
tuple_data = ((1,2,3),
(4,5,6),
(7,8,9))
data = np.array(tuple_data)
print(data)
[[1 2 3] [4 5 6] [7 8 9]]
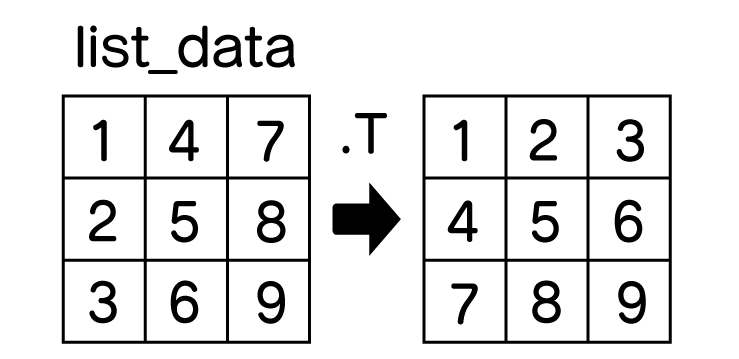
最後にdictから作ります。辞書データをnumpyにしますが、key値を無視しています。
# dictデータから
dcit_data = {'a':[1,4,7],
'b':[2,5,8],
'c':[3,6,9]}
# 一旦リストデータに変換 a,b,cのkey情報は消える
list_data = [dcit_data[k] for k in dcit_data.keys()]
data = np.array(list_data).T
print(data)
[[1 2 3] [4 5 6] [7 8 9]]
a列=[1, 4, 7]のデータというイメージでいるので、np.array(list_data).T(転置行列)で向きを変えています。
for文は内包表記を使っています。見たことない方は、下記記事参照ください。
-

-
参考【python 入門】list(リスト)の内包表記の書き方、使い方
続きを見る
ファイルからデータを作る
ファイルからデータを読み込んで、numpyのデータを作りましょう。
次のtxtファイルを読み込みます。

# テキストファイルから
with open('sample_data.txt') as f:
list_data = [d.rstrip() for d in f.readlines()]
data = np.array(list_data)
print(data)
['1' '2' '3' '4' '5' '6' '7' '8' '9' '10']
readlines()で1行ずつ読み取り、rstrip()で余分な改行文字を消しています。
次のCSVを読み込みます。
# CSVファイルから
with open('sample_data.csv') as f:
list_data = [d.rstrip().split(',') for d in f.readlines()]
data = np.array(list_data)
print(data)
ほとんど、txtと同じですが、CSVファイルなので、split()を使ってカンマを分割しています。
画像からデータを作る
画像の読み込みもnumpyのデータになります。
画像読み込みにはopencvを使います。
インストール必要な方は、他のライブラリ同様pipでインストールしてください。
pip install opencv-python
次の猫を読んでみます。

# 画像データから
import cv2
img = cv2.imread('cat.jpg')
print('画像サイズ', img.shape)
print('データタイプ', type(img))
画像サイズ (640, 613, 3) データタイプ <class 'numpy.ndarray'>
データのサイズが3次元であることがわかります。
縦横以外にRGBの色情報があるためです。
データを計算する
次に計算をしていきます。
numpyではブロードキャスト(形状の自動変換)いう考えがあるので、しっかり理解していきましょう。
四則演算
最初に、同じ行数、列数のデータを足し算します。
# 四則演算
data1 = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
data2 = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
data = data1 + data2
print(data)
[[ 2 4 6] [ 8 10 12] [14 16 18]]
これは、それぞれ対応する要素が足されていることがわかりますね。
他の四則演算は-(引く)、*(掛ける)、/(割る)ですので、各自試してみてください。
次に、data2の行数、列数が違った場合を考えます。
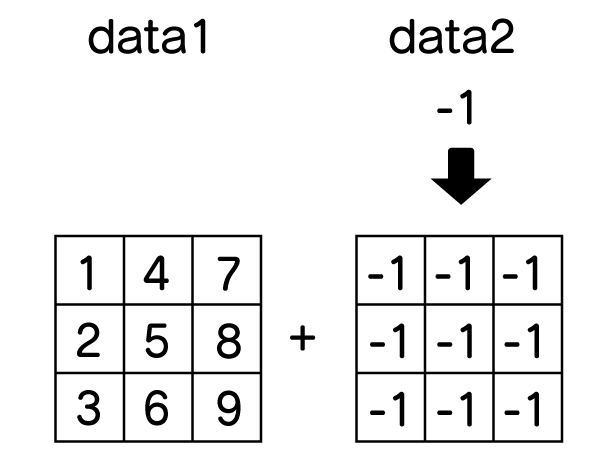
まず、数値が1つの場合
# 数値が1つ
data1 = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
data2 = -1
data = data1 + data2
print(data)
[[0 1 2] [3 4 5] [6 7 8]]
全部に-1が足されています。
これはどういうことかというと、次のように変換されて、足されているイメージです。
次は、列数が一致している場合を計算します。
# 列数が合っている
data1 = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
data2 = [[-1,-2,-3]] #1次元に3つ (1,3)
data = data1 + data2
print(data)
[[0 0 0] [3 3 3] [6 6 6]]
この場合は、1行を3行文複製しています。
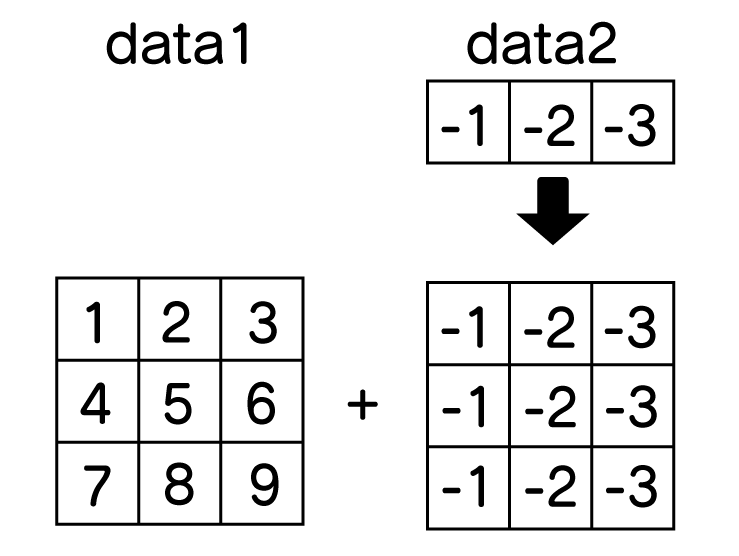
行数が一致している場合も同じです。
# 行数があっている
data1 = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
data2 = [[-1],[-2],[-3]] # (3,1)
data = data1 + data2
print(data)
[[0 1 2] [2 3 4] [4 5 6]]
行列演算
numpyでは行列演算もできます。
dot()を使って、行列の積を計算します。
# 行列演算
data1 = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
data2 = [[-1],[-2],[-3]]
data = np.dot(data1, data2)
print(data)
[[-14] [-32] [-50]]
どうでしょう?numpyがどういったもので、どういうことができるかわかったでしょうか?