
前回、GoogleのVisionAPIをつかってOCRをしました。
>> Google Vision API OCRで帳票画像のデータ化
ほかにもtesseractをつかったOCRがあります。
比較評価としてこちらもやってみます。
本記事はこんな方におすすめです。

本記事の内容
- tesseractのインストール
- pyocr+tesseractの使い方
この記事を読むと、pyocr+tesseractによるOCRができるようになります。
*Windowsが対象になります。
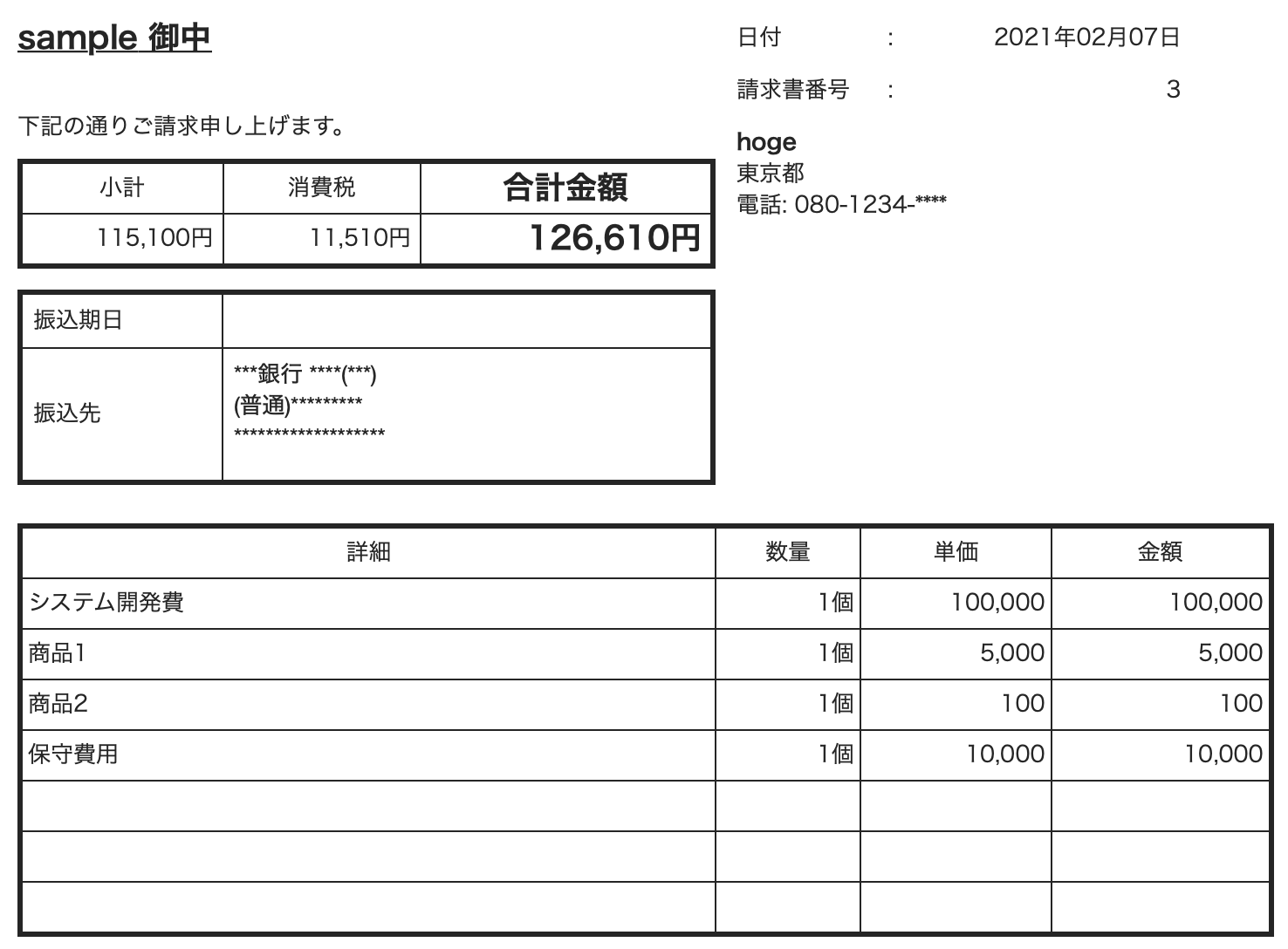
今回は、左の画像を右のようにデータ化します。
Vision APIでOCRで使った帳票をそのまま使っていますが、これを見ても帳票のデータ化ができないことがわかりますね。
座標データがないので難しいです。
座標データの関係ない、短い文章とかでは使えそうです。
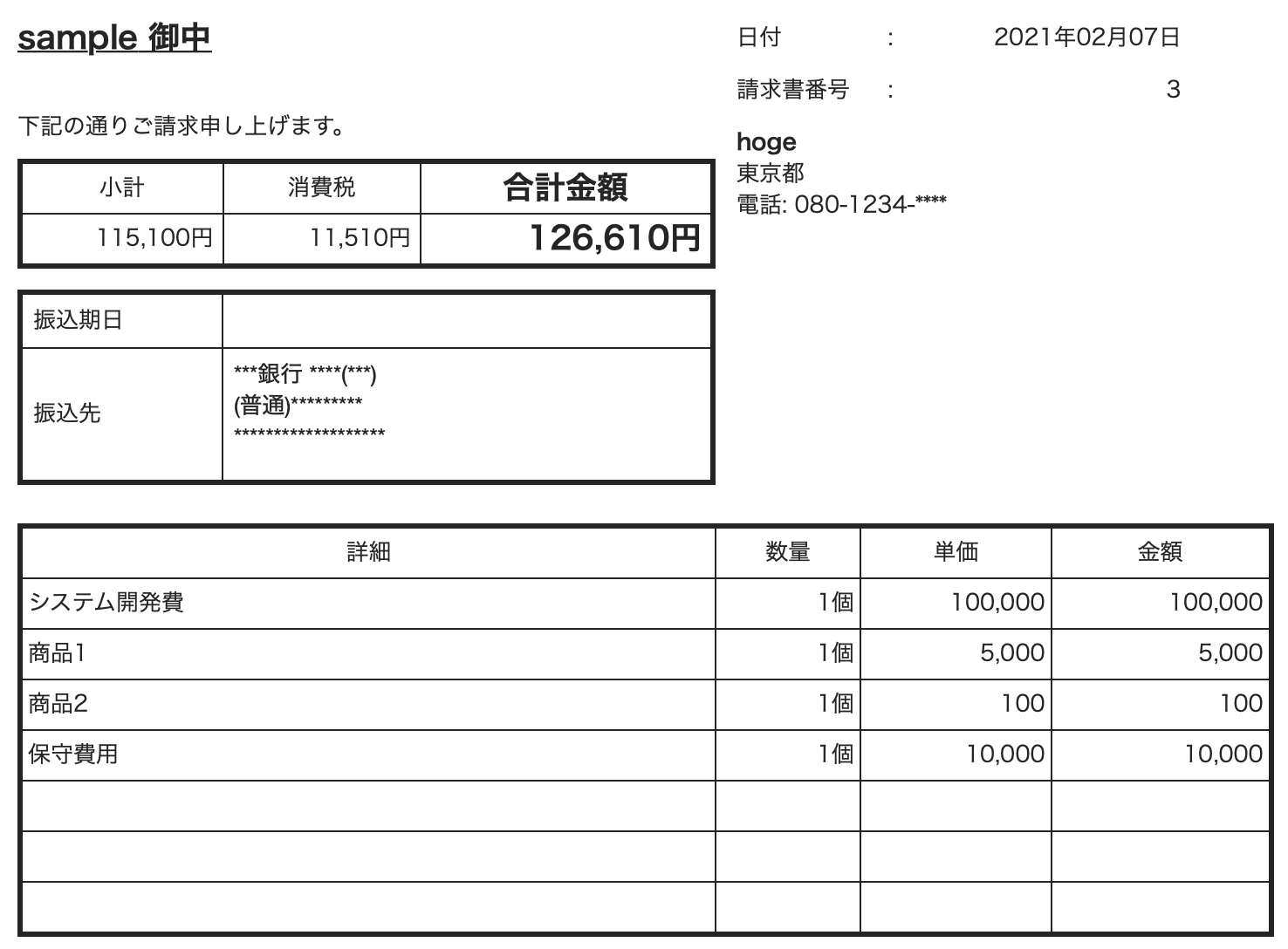
sample “,下記の通りご請求申上上げます。,小計,115,100円,
システム開発費,商品1,商品2,保守費用,消費税,11.510円,
ww銀行 |,ar、靖kkk,(普通),KK,合計金額,126,610円,日付,
請求書番号,hoge,東京都,2021年02月07日,電話: 080-1234-*",
1個,1個,1個,1個,単価,100.000,5.000,100,10.000,3,
金額,100.000,5.000,100,10.000
tessreractインストール
下記リンクからインストーラをダウンロードします。
Nextを押します。
I Agreeを押します。
ユーザーの選択はどちらでもOK。Nextを押します。
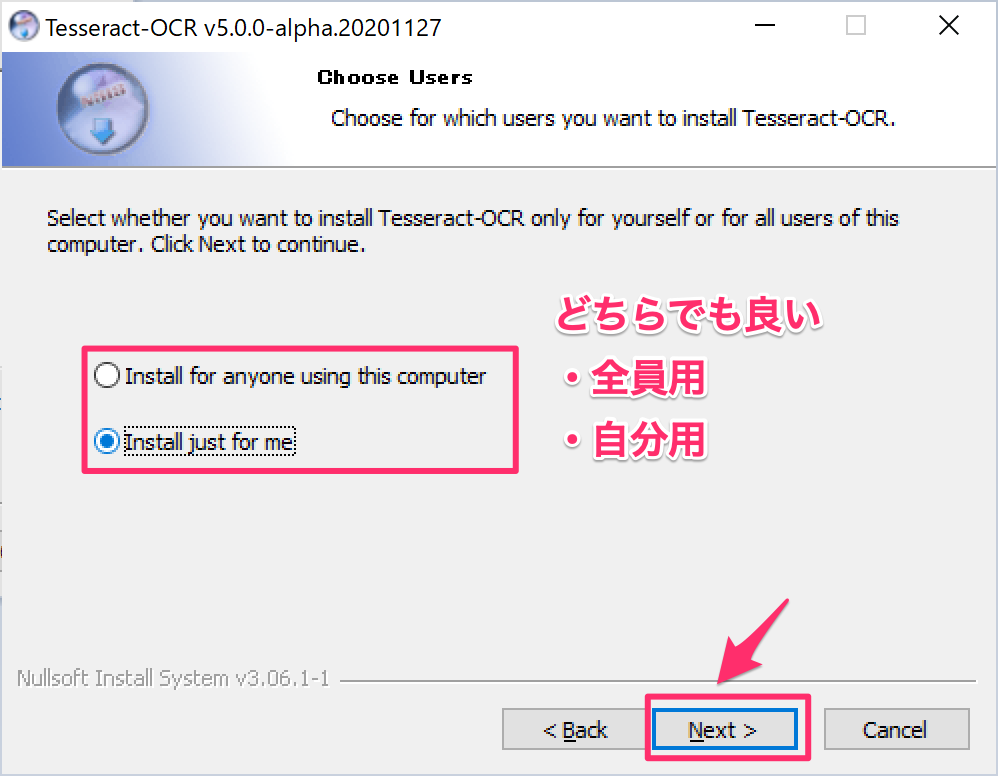
線の箇所の「+」から、2つチェックする。
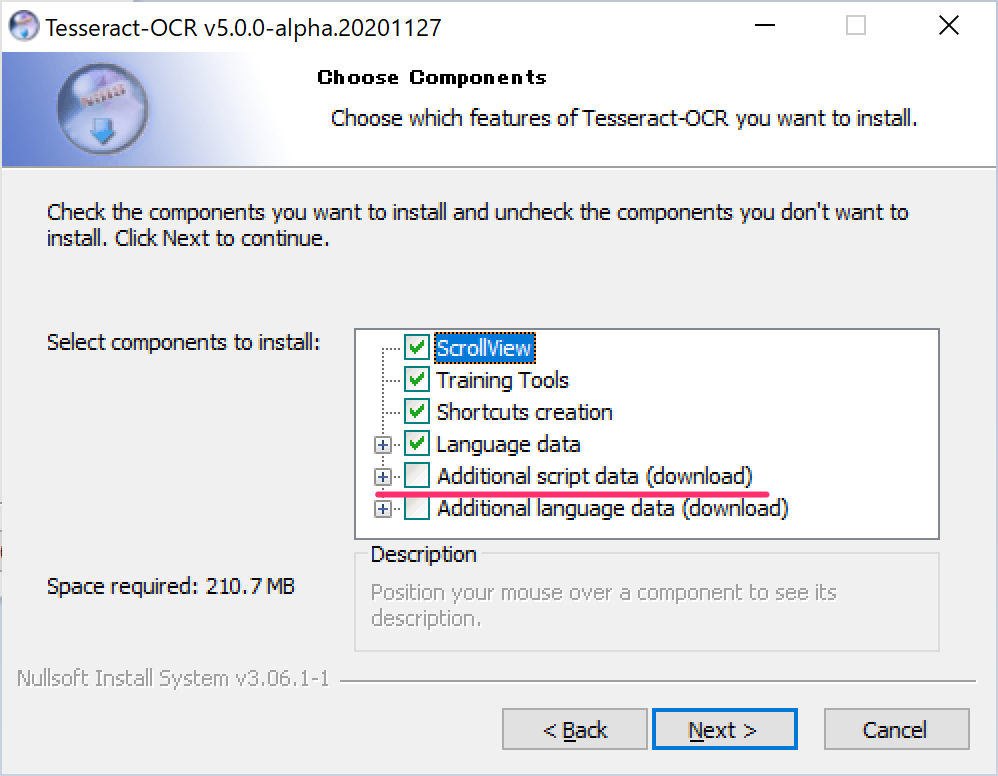
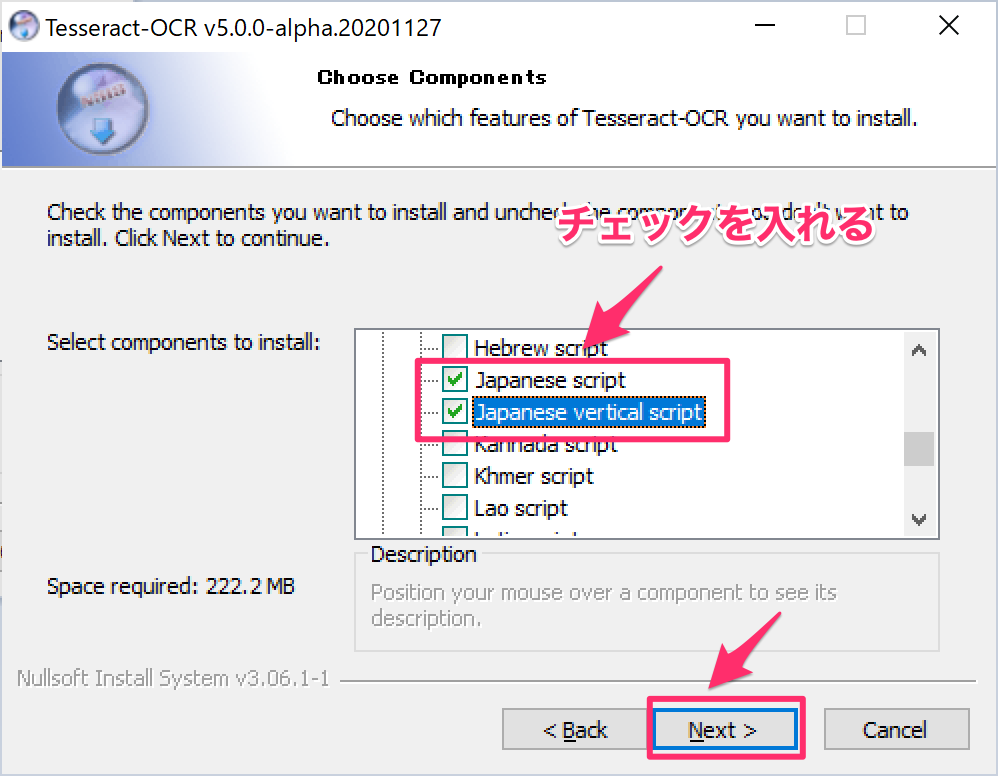
次も、線の箇所の「+」から、2つチェックする。
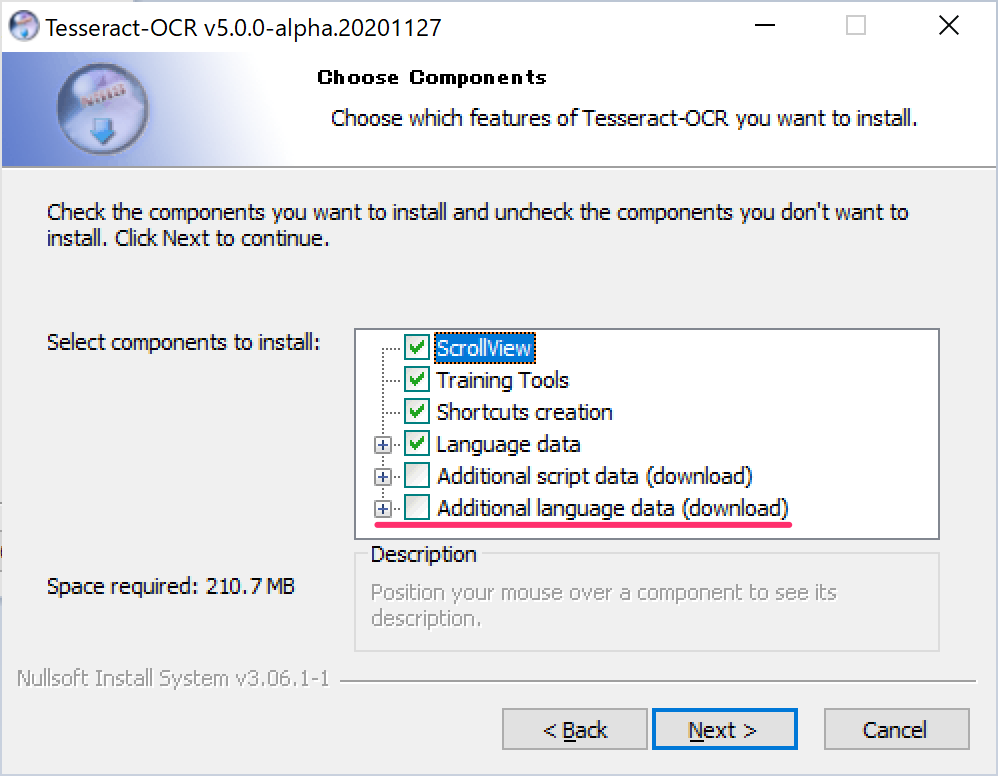
インストール先を確認して、Nextを押します。
Installを押します。
Nextを押します。
Finishを押して、完了です!
pyocrインストール
pyocrライブラリが必要になります。
pipを使ってインストールしましょう。
pip install pyocr
そのほかにも、以下のライブラリをインストールしてください。
Pillow opencv-python numpy
使い方
次の手順で実装します。
実装流れ
- pyocrでtesseractを読み込み
- 画像取得+画像処理(必要に応じて)
- OCR実行
- 文字の取得
ライブラリ読み込み
まず、ライブラリ読み込みます。
from PIL import Image import pyocr import pyocr.builders import cv2 import numpy as np
OCRの関数用意
画像ファイルのパスを引数にした関数にします。
def render_doc_text(file_path):
# ツール取得
pyocr.tesseract.TESSERACT_CMD = 'C:/Users/hi_tu/AppData/Local/Programs/Tesseract-OCR/tesseract.exe'
tools = pyocr.get_available_tools()
tool = tools[0]
# 画像取得
img = cv2.imread(file_path, 0)
img = Image.fromarray(img)
# OCR
builder = pyocr.builders.TextBuilder()
result = tool.image_to_string(img, lang="jpn", builder=builder)
# 結果から空白文字削除
data_list = [text for text in result.split('\n') if text.strip()]
data_list
return data_list
ポイント
pyocr.tesseract.TESSERACT_CMD = インストールしたtesseractのパス
は変更してください。
そのままの画像でも良いのですが、検出精度上がらないか模索してみました。
帳票の線を消す画像処理を追加してみました。
def render_doc_text(file_path):
# ツール取得
pyocr.tesseract.TESSERACT_CMD = 'C:/Users/hi_tu/AppData/Local/Programs/Tesseract-OCR/tesseract.exe'
tools = pyocr.get_available_tools()
tool = tools[0]
# 画像取得
img = cv2.imread(file_path, 0)
# 必要に応じて画像処理 線を消す
ret, img = cv2.threshold(img, 150, 255, cv2.THRESH_BINARY)
img = cv2.bitwise_not(img)
label = cv2.connectedComponentsWithStats(img)
data = np.delete(label[2], 0, 0)
new_image = np.zeros((img.shape[0], img.shape[1]))+255
for i in range(label[0]-1):
if 0 < data[i][4] < 1000:
new_image = np.where(label[1] == i+1, 0, new_image)
cv2.imwrite('sample_edited.png', new_image)
img = Image.fromarray(new_image)
# OCR
builder = pyocr.builders.TextBuilder()
result = tool.image_to_string(img, lang="jpn", builder=builder)
# 結果から空白文字削除
data_list = [text for text in result.split('\n') if text.strip()]
data_list
return data_list
左が画像処理前、右が画像処理後

色々画像処理は試しても、結果的には安定した検出が難しかったです。
GoogleのOCRがすごいということが改めてわかります。
実行
最後に作った関数を実行します。
# OCR検知
data_list = render_doc_text('sample.png')
print(','.join(data_list))
sample “,下記の通りご請求申上上げます。,小計,115,100円, システム開発費,商品1,商品2,保守費用,消費税,11.510円, ww銀行 |,ar、靖kkk,(普通),KK,合計金額,126,610円,日付, 請求書番号,hoge,東京都,2021年02月07日,電話: 080-1234-*", 1個,1個,1個,1個,単価,100.000,5.000,100,10.000,3, 金額,100.000,5.000,100,10.000
認識はしているけど、帳票データには向かないですね。
お客様アンケートなど手書きの文書など精度が悪くてもいいから、データ化しておきたい時とかであれば使えそうですね。
メリットは完全に無料でできるところですので、大量に画像処理したくて、Googleの請求が嫌な方は使ってみると良いでしょう。