
画像AIは分類と物体検知がよく使われる技術です。
物体検知は2016年にSSD、YOLOという方法がでてから、一気に使われるようになりました。
よく使われますが、中身はとてもややこしいです。
私は、頑張って理解してもすぐ忘れてしまいます。
本記事はこんな方におすすめです。

物体検知についてなんとなく知っておきたい
本記事の内容
- 物体検知の方法
- 学習済みAIを使う方法
今回は、3回に分けて、この技術の使い方を紹介していきます。
3ステップ
- 学習済みAIを使ってみる 👈 本記事はここ
- データの準備
- AIを学習
今回は、1つ目の「学習済みAIを使ってみる」になります。
目次
物体検知について
物体検知には、有名なYOLOとSSDの2種類があります。
ほかにもCenterNetもありますが、YOLO、SSDがよく使われています。
私は最初にYOLOのほうをCouseraのDeepLearning講座で知りました。
Andreq Ng先生が難しい内容をわかりやすく説明してくれてましたが、それでも理解するのが大変でした。。。
最初はKeras(AIライブラリ)+YOLOをよく使っていましたが、今回はPytorch(AIライブラリ)SSDで進めていきます。
SSDの論文の図を引用すると、AI構造は下記のようになっています。
左に画像(高さ×幅×3ch)を入力して、右に行くと小さい立方体のデータになっていくような構造です。
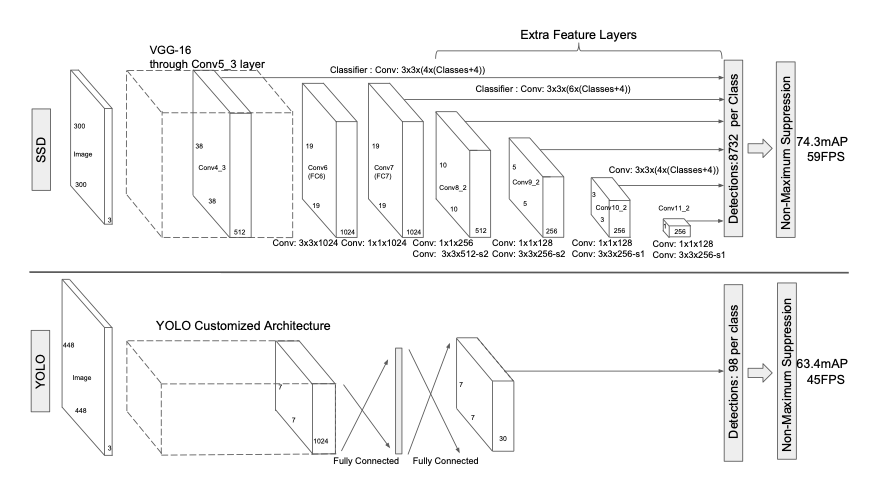
構造に違いはありますが、やっていることは似ています。
入力画像を小さい特徴マップにしていき、物体(オブジェクト)がどこにあるのか計算させています。
下記図の例では、300×300の画像を8×8の特徴マップにして、各マスでここは犬、ここは猫のように検知します。
これで、検知できてしまうのは、8×8の特徴マップで検知できるように学習しているということです。
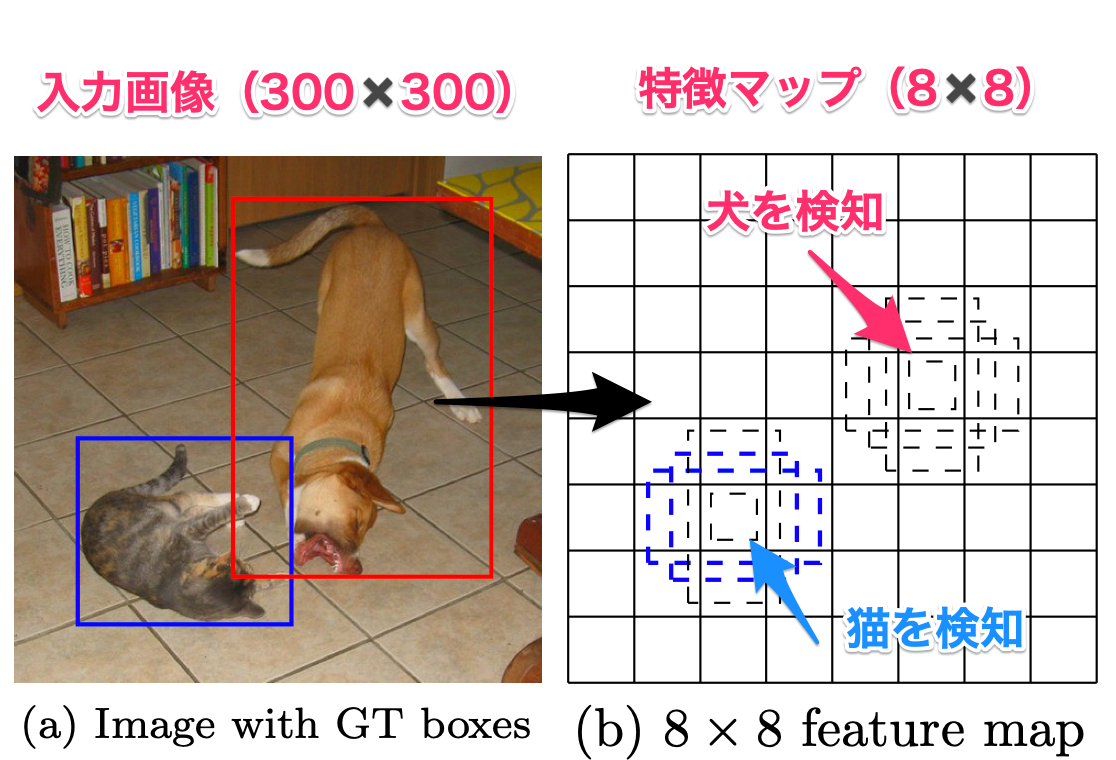
SSDのほうが、特徴マップはサイズ別に6つを使うので、出力されるデータが多くなります。
実際に、画像を入力するとAI構造から出力されるデータは、2つ
・検知したい物体の確信度がわかる8732個×物体の種類数
・8732個の検出する四角(Box)のオフセット値
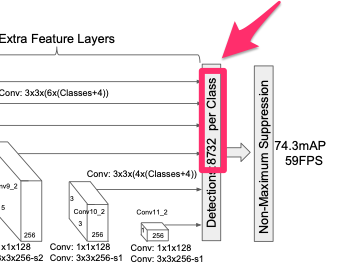
このデータを処理すると、画像から犬や猫が高さと幅の四角で検出できるようになります。
この処理の仕方がこの位置検出では難しいところです。
学習済みAIを使ってみる
まず最初は、学習済みのAIを使ってみましょう。
学習済みのAIはすでに、誰かが、たくさんの画像を使ってAIのモデルを学習してくれたものになります。
使う際のデメリットは、自分が検出したいものが入っていないことが多いということです。
今回は、pytorchの公式のSSDのページを参考にします。
必要なライブラリ
次の2つのライブラリが必要になります。
必要なライブラリ
- matplotlib
- pytorch
1つ目はpip install matplotlibですが、2つ目のpytorchは下記を参考にしてください。
OSやGPU使うかなどによって違います。
では、実装していきましょう。
といっても、pytorchのサイトにあるコードをそのまま使います。
モデル読込
まずは、学習済みのモデルを読み込みます。
学習済みモデル以外にも、データの処理をしてくれる機能も読みます。
import torch
precision = 'fp32'
ssd_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd', model_math=precision)
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')
ssd_model:学習済みモデル
utils:データの処理機能
モデルを推論モードに変更
モデルをCPUで動かす設定にして、推論モード(eval)にします。
GPUで使い場合は、'cpu'を'cuda'に変更します。
推論モードというのは、学習ではなくて、実際にシステムなどで使うときのモードです。
推論時と学習時では、AIモデルの処理が違う場合があります。
例えば、ドロップアウト層の落とす率とかですが、知らなくても大丈夫です。
# CPUで動くようにして、推論モード
ssd_model.to('cpu')
ssd_model.eval()
検知したい画像の読み込み
モデルの準備ができたので、次はデータを準備していきます。
今回コードでは、コードと同じところに「od_dogs」というフォルダを置いて、そこに犬のデータを何個か入れてあります。
検知したい画像の場所をリストにします。
import glob
# 検出する画像リスト
img_files = glob.glob('od_dogs/*.jpg')
uris = [
img_files[0],
img_files[1],
]
リストにしたデータをpytorchで処理できるように処理します。
# 入力データ作成
inputs = [utils.prepare_input(uri) for uri in uris]
tensor = utils.prepare_tensor(inputs, precision == 'fp16')
tensor = tensor.to('cpu')
AIモデルに入れる入力データもCPU用に切り替えています。
注意ポイント
AIモデルがGPU用、入力データがCPU用となっているとエラーになります。
検知(推論)処理
では早速、準備したデータをAIモデルに放り込んで、検知していきましょう。
今回の場合は、画像に写っている犬の場所を検知していきます。
一般的には、推論すると言います。
推論の処理は次のようになります。
# 検知
with torch.no_grad():
detections_batch = ssd_model(tensor)
読み込んだ、ssd_modelに先ほど準備したデータのtensorを入れただけです。
detections_batchに推論結果が入ります。
torch.no_grad()は勾配計算をしないということですが、推論の時のおまじないです。
>> 参考 pytorchドキュメント torch.no_grad
検知した内容も少し見ていきましょう。
どういう形のデータが返ってきているか見てみます。
print('各ボックスのオフセット', detections_batch[0].shape)
print('各ボックスの信頼度', detections_batch[1].shape)
各ボックスのオフセット torch.Size([2, 4, 8732]) 各ボックスの信頼度 torch.Size([2, 81, 8732])
オフセットの方は(入力データ数、オフセットデータ、検出するボックス数)になります。
信頼度の方は(入力データ、分類数、検知するボックス数)になっています。
検出するボックス数=8732なのは、冒頭で紹介した、AIモデルの出力がそうなっているからです。
分類数は81となっていますね。
実際に検知したい種類は、80種類です。
次のコードで確認することができます。
# 検知する種類 犬とか人とか80種類
classes_to_labels = utils.get_coco_object_dictionary()
print(classes_to_labels)
print('クラス数', len(classes_to_labels))
['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'] クラス数 80
これらに背景=(何も検知されない)を足した81種類になります。
検知したデータの表示
このままのデータでは、使い方が分かりませんね。
ちゃんと、使いやすいように変換してくれる機能がついています。
次のようになります。
# 結果取得 results_per_input = utils.decode_results(detections_batch) best_results_per_input = [utils.pick_best(results, 0.40) for results in results_per_input]
このbest_results_per_inputに分かりやすい形でデータが変換されました。
1つ目だけ確認してみましょう。
# 1つ目の結果
bboxes, classes, confidences = best_results_per_input[0]
print('検知ボックス', bboxes)
print('検知クラス', classes, classes_to_labels[classes[0]-1])
print('確信度', confidences)
検知ボックス [[0.29505098 0.10033807 0.91788054 0.9388586 ]] 検知クラス [17] dog 確信度 [0.9243633]
検知された、場所や種類、確信度がわかるようになります。
検知されたクラスは背景ぶんを-1します。
あとは、これをmatplotlibで表示してみます。
from matplotlib import pyplot as plt
import matplotlib.patches as patches
for image_idx in range(len(best_results_per_input)):
fig, ax = plt.subplots(1)
# Show original, denormalized image...
image = inputs[image_idx] / 2 + 0.5
ax.imshow(image)
# ...with detections
bboxes, classes, confidences = best_results_per_input[image_idx]
for idx in range(len(bboxes)):
left, bot, right, top = bboxes[idx]
x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r', facecolor='none')
ax.add_patch(rect)
ax.text(x, y, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1], confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
plt.show()
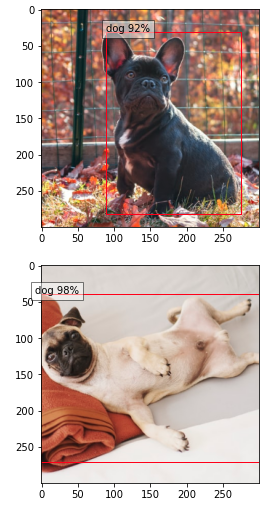
ちゃんと検知できていますね。
他の画像でも色々試してみたください。
次は、自分のデータで学習した人向けに、データの準備です。
-

-
参考【python AI】物体検出の実装方法 -データの準備-
続きを見る