
2015年前後から、クラウドサービスが色々と出てきました。
簡単に、AI、チャットボットが使えたり、データベースやストレージを借りることもできます。
今回は、画像のAIで画像の中から文字を検出してくれるOCRについて紹介します。
本記事はこんな方におすすめです。

お客様アンケートの集計を自動化したい
本記事の内容
- GCPでのAPI設定
- 方法その1 ウェブリクエスト
- 方法その2 ライブラリ
- 検出したデータを処理
この記事を読むと、Google Cloud PlatformのAPIの設定から、Vision APIでOCRが使えるようになります。
今回は、左の画像を右のようにデータ化します。
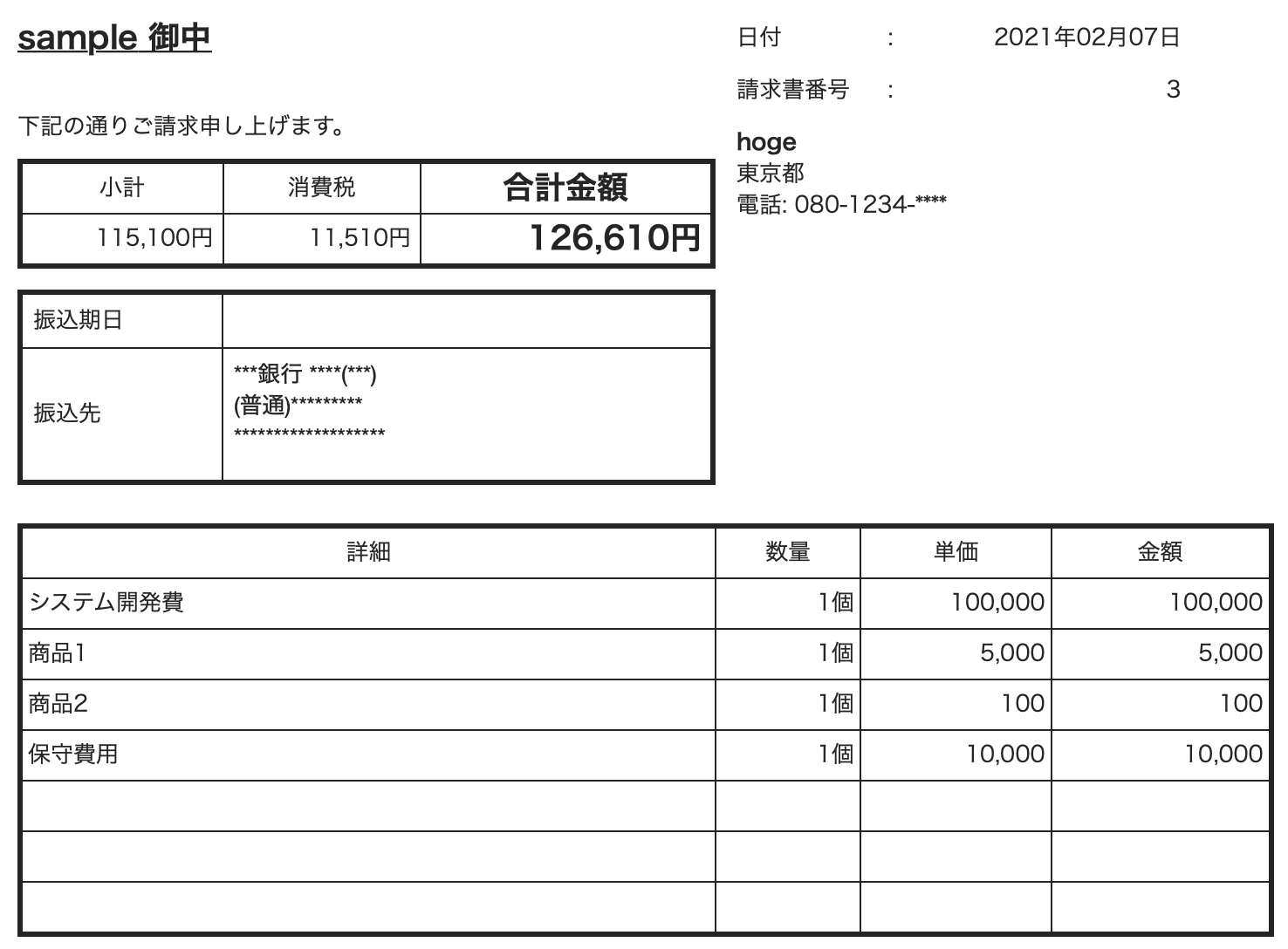
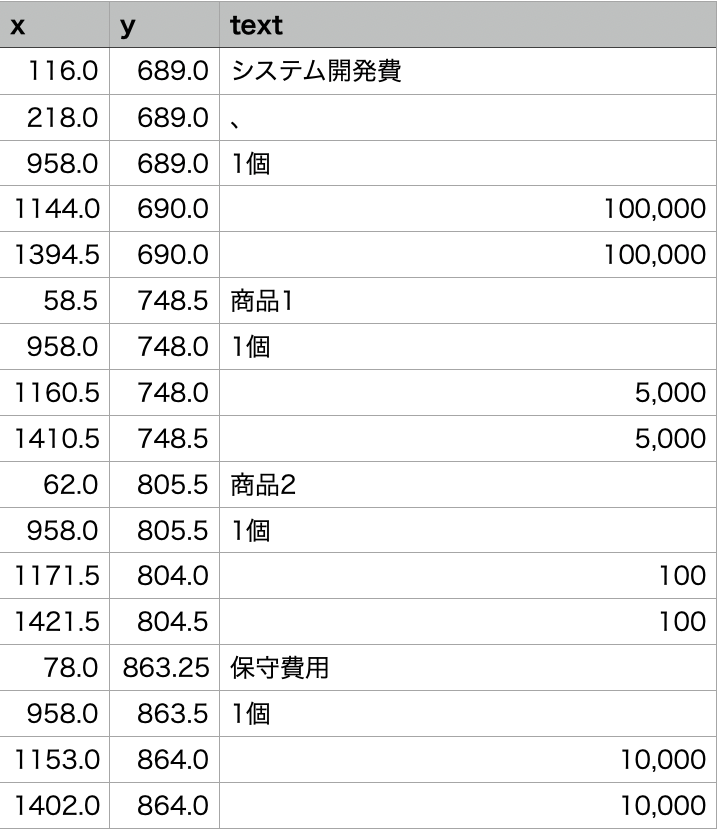
*データは一部
目次
GCP VisionAPIの価格
まず、気になるのは利用料金ではないでしょうか?
価格は次のリンクの公式にのっています。

データ1000までは無料ですね。
そのあと、1000ごとに$1.50かかりますが、200円もしないので、ほとんど気にする必要はないでしょう。
このように、簡単にすぐ使える上に、とても安く提供されています。
GCPでのAPI設定
VisionAPIをGCPで有効にしていきます。
GCPについて
GCPはGoogleCloudPlatformの略です。
AmazonのAWSやIBM Cloud、WindowsのAzureと同じクラウドサービスです。
サーバーが簡単に構築できたり、AIの処理の実装などを手伝ってくれます。
まず、GCPにアクセスします。
プロジェクトの作成
GCPではプロジェクト単位で使うサービスなどを管理できます。
まず、プロジェクトを作成します。
GCPのダッシュボードの「プロジェクト選択」から「新しいプロジェクト」を選択します。
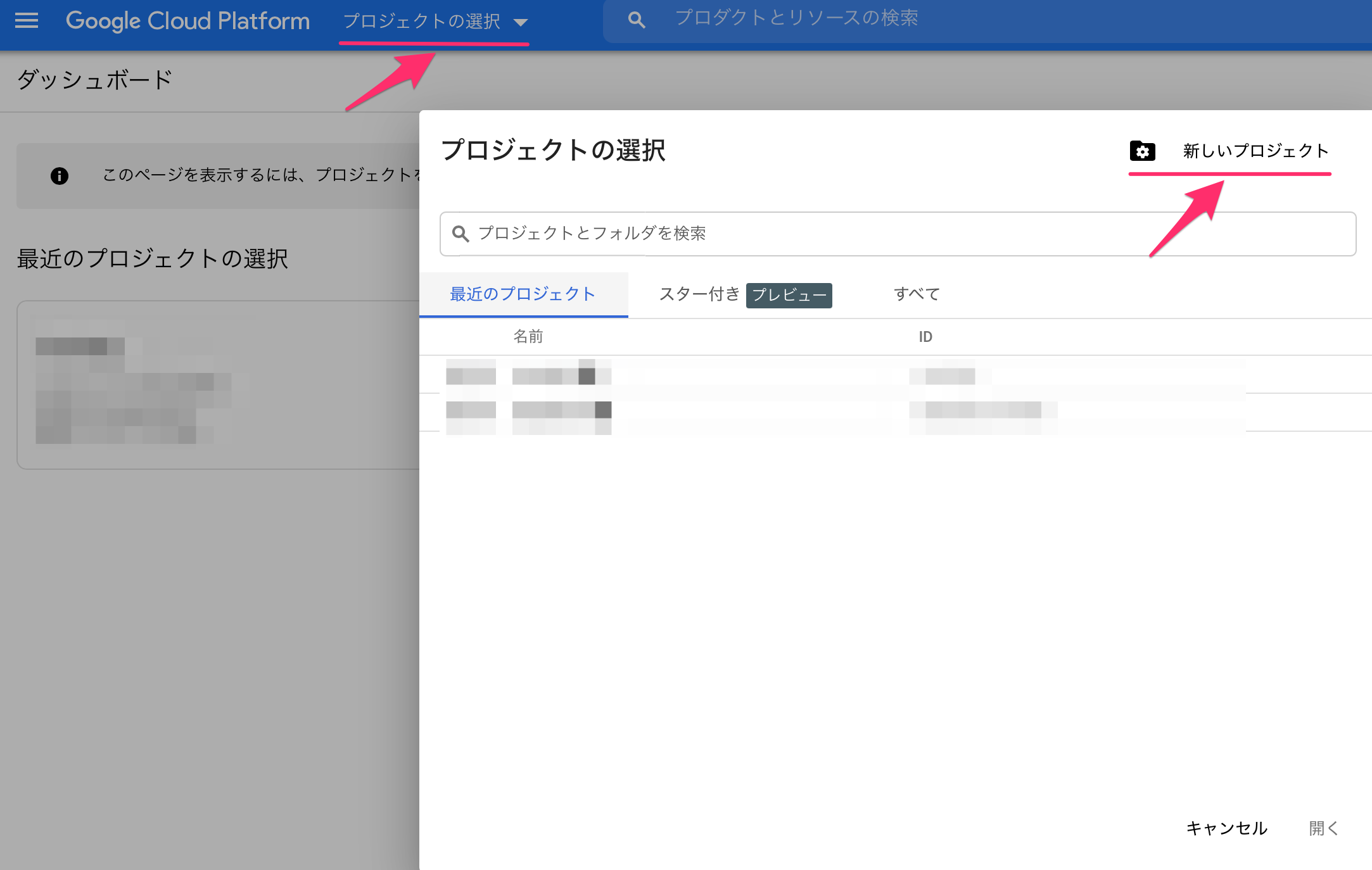
もしくは、下記のリンクに直接飛びます。
適当な名前でプロジェクトを作成します。
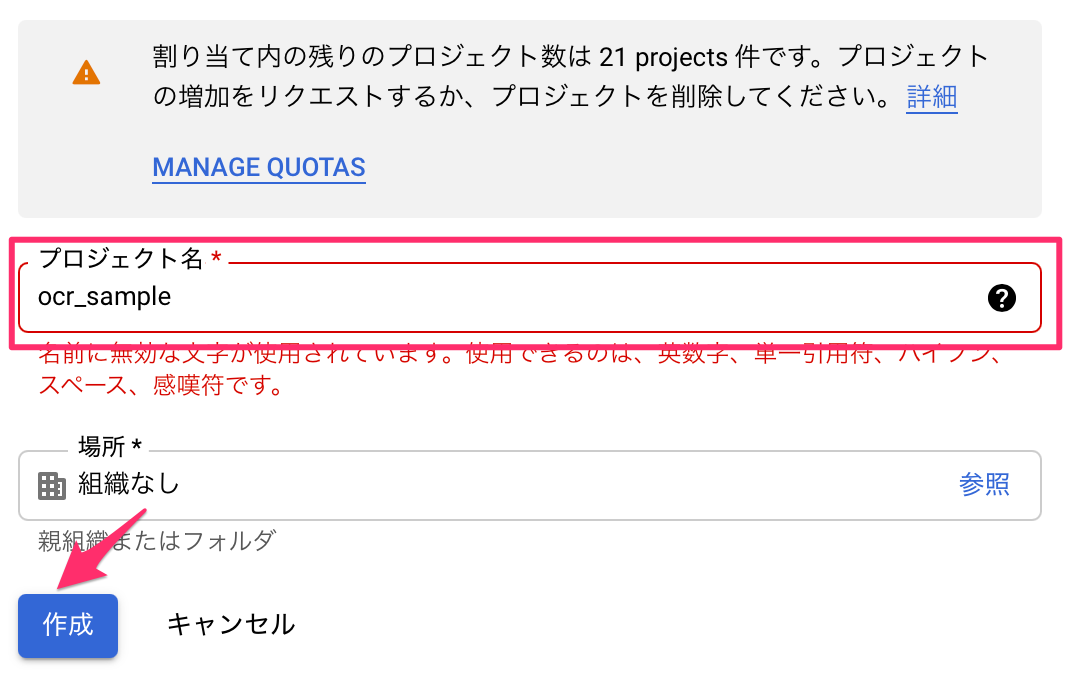
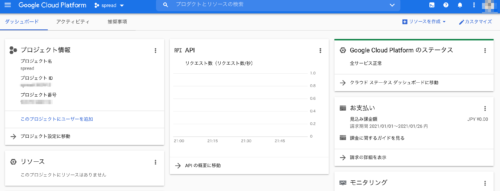
これで、新しいプロジェクトが作成され、次のようなダッシュボードがもらえます。
ここで、色々なサービスを管理します。
Vision APIを有効にする
VisionAPIを使えるようにします。
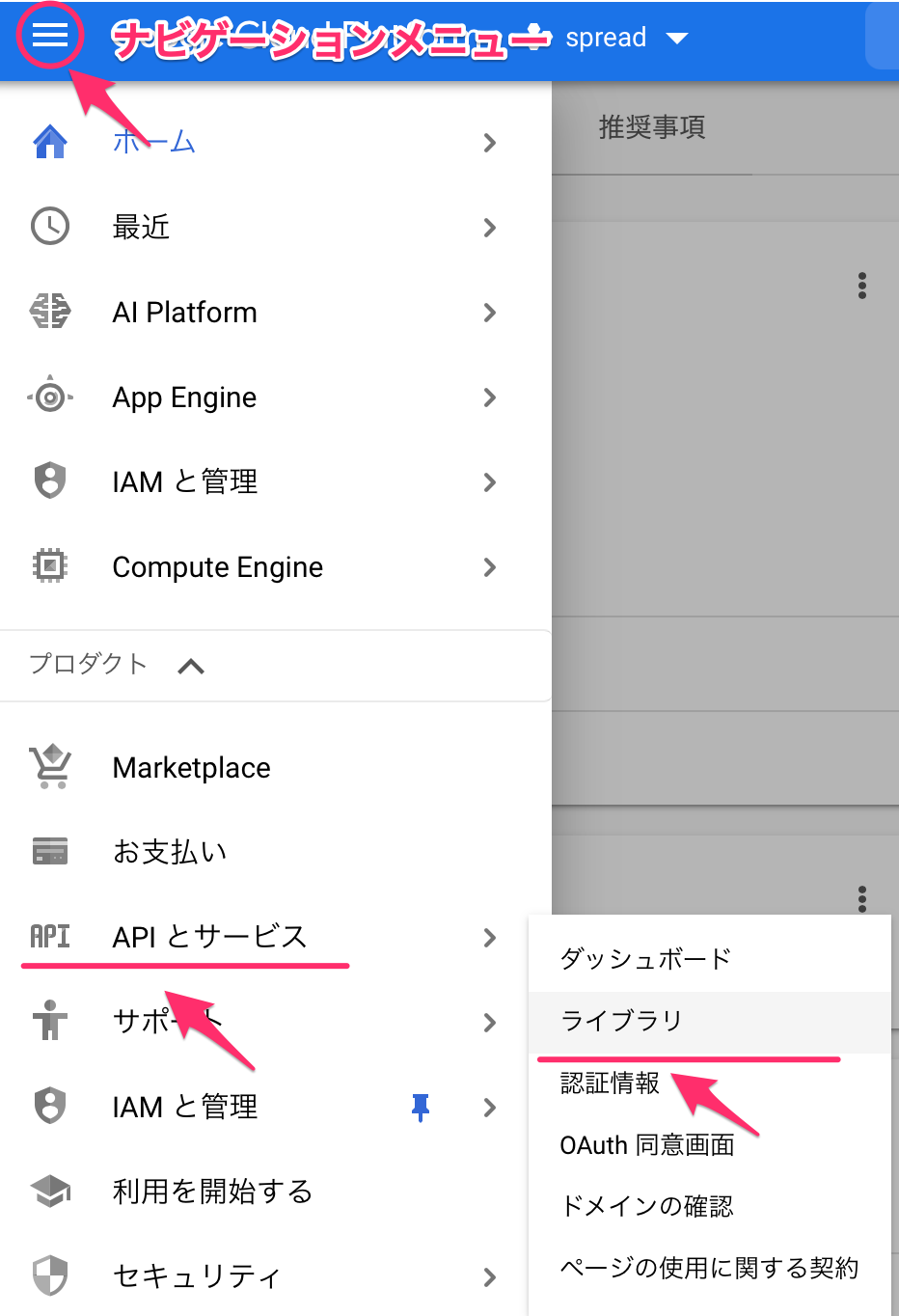
ナビゲーションメニューより、API>ライブラリを選択します。
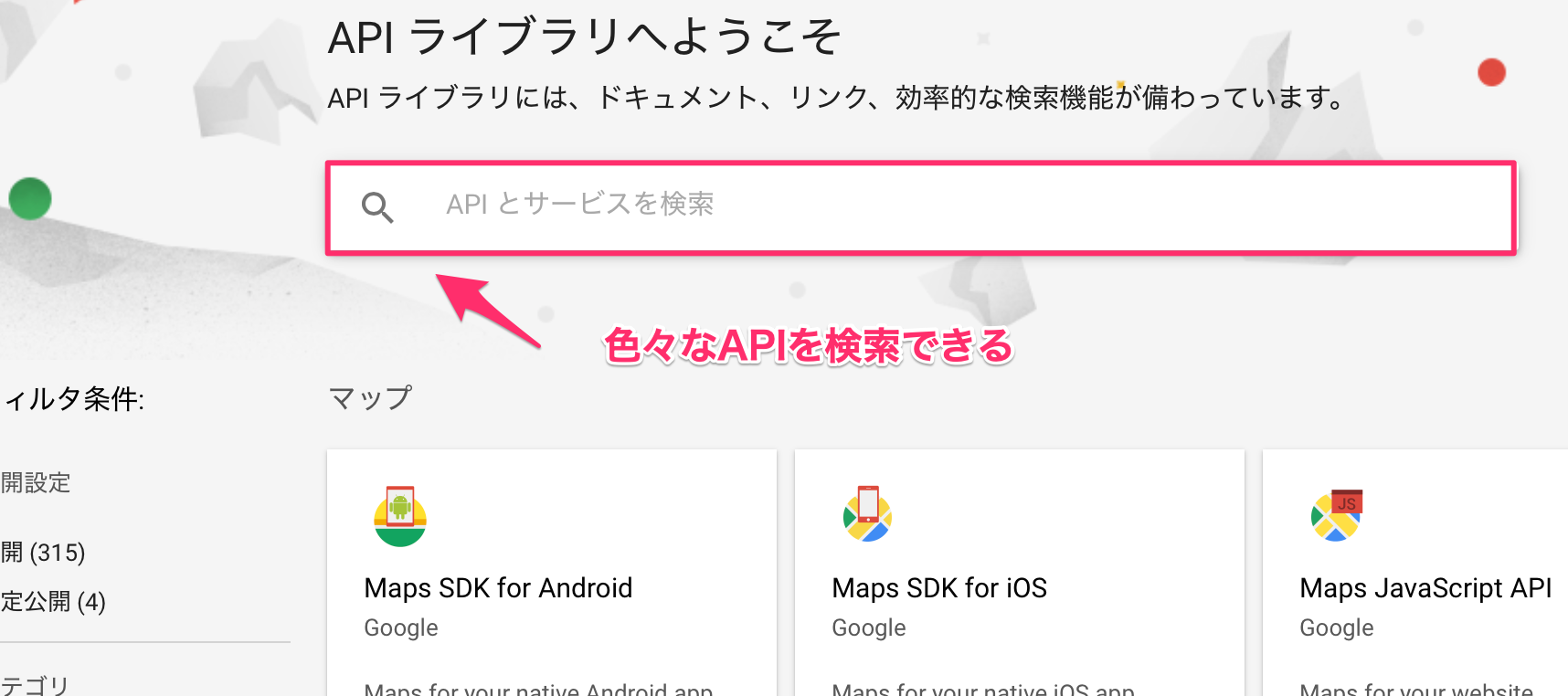
次に、Vision APIを検索します。
「vition api」を入力して、Vision APIを選びます。
APIを有効にします。

これで必要なAPIを有効にしたので、接続するための認証情報を作っていきます。
Google APIの認証を取得
ナビケーションメニューから、API>認証情報へいきます。
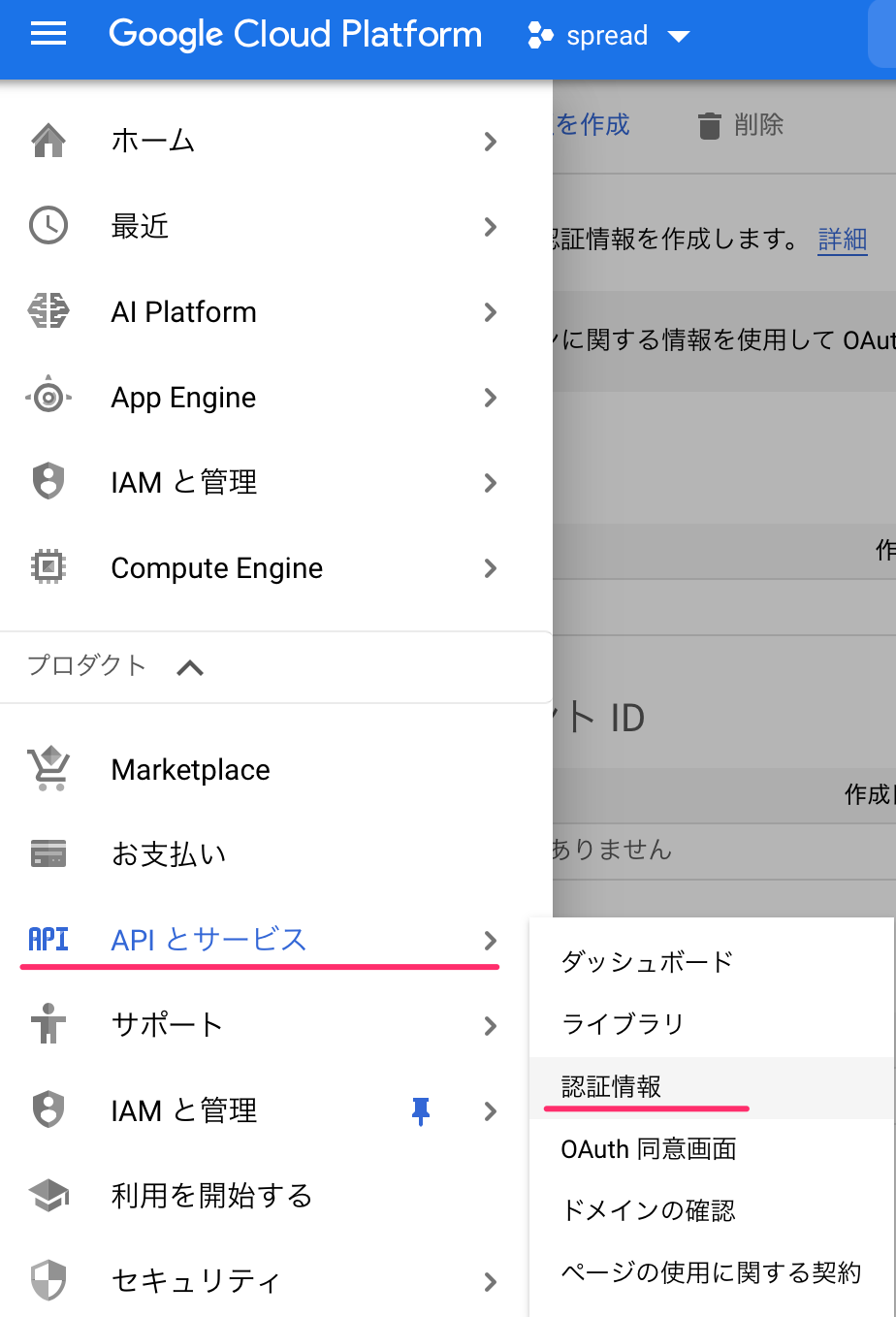
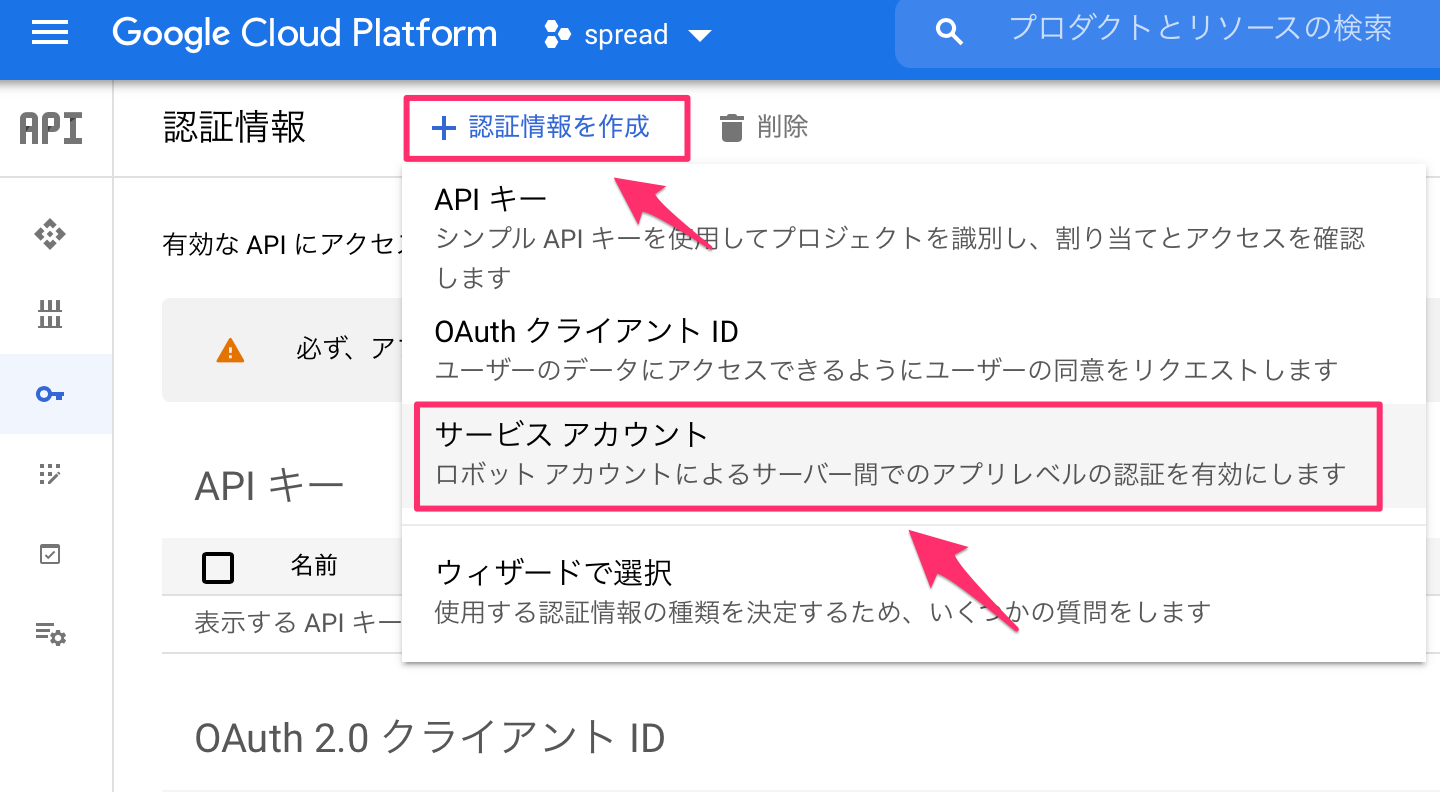
認証情報を作成から、サービスアカウントを作成します。
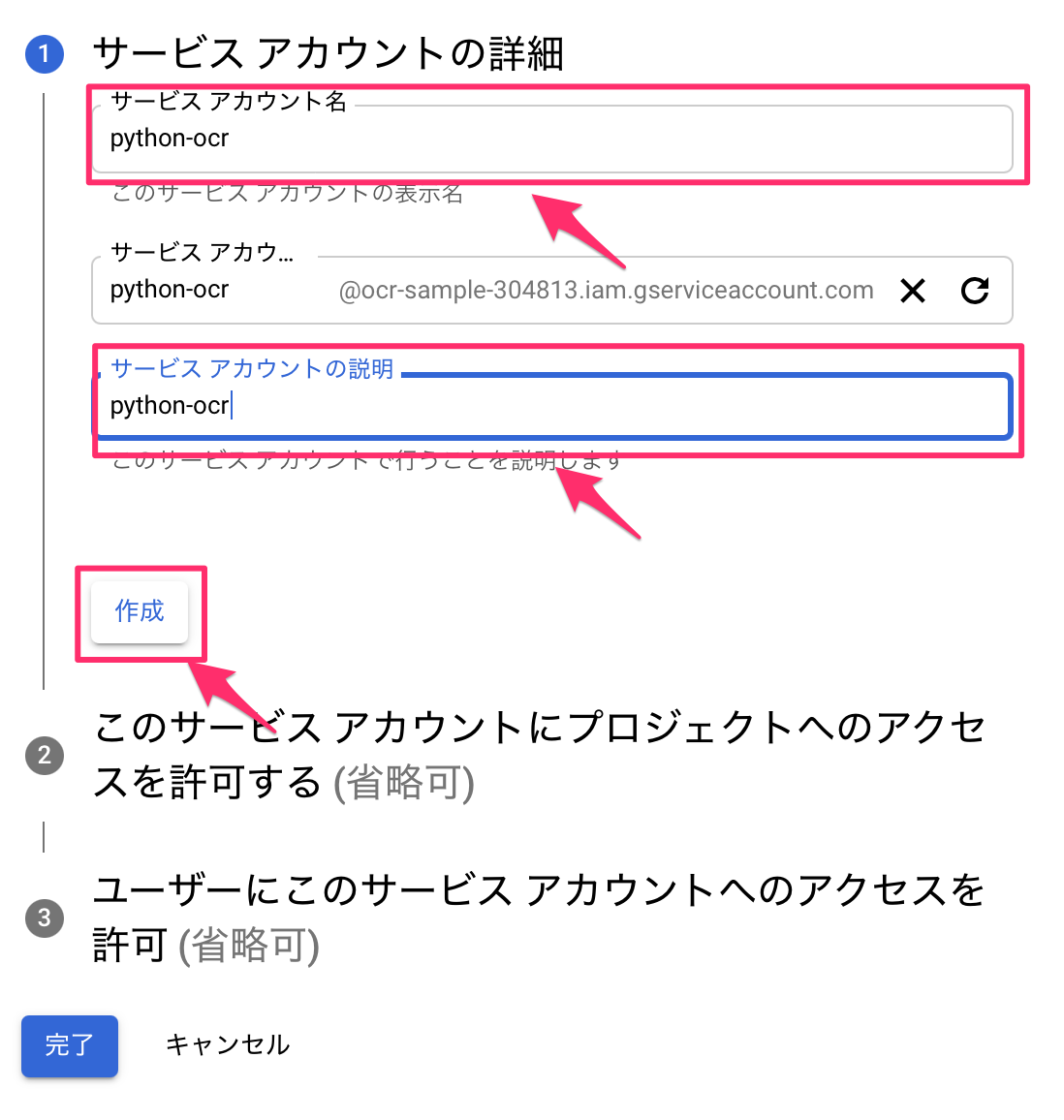
サービスアカウント名と説明を入力して、作成を押します。
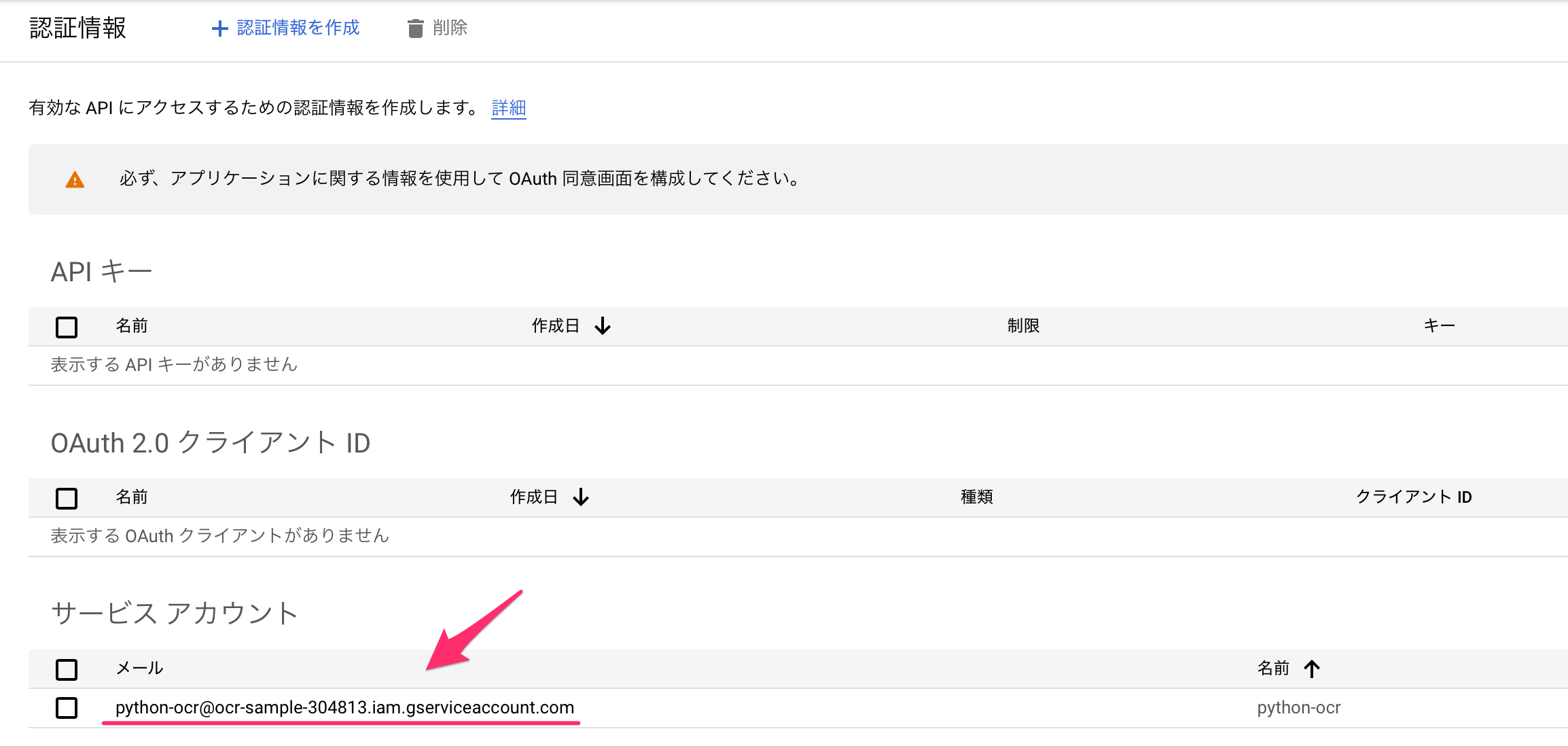
サービスアカウントができるので、リンクを押します。
キーの項目から、鍵を追加から新しい鍵を作成を押します。
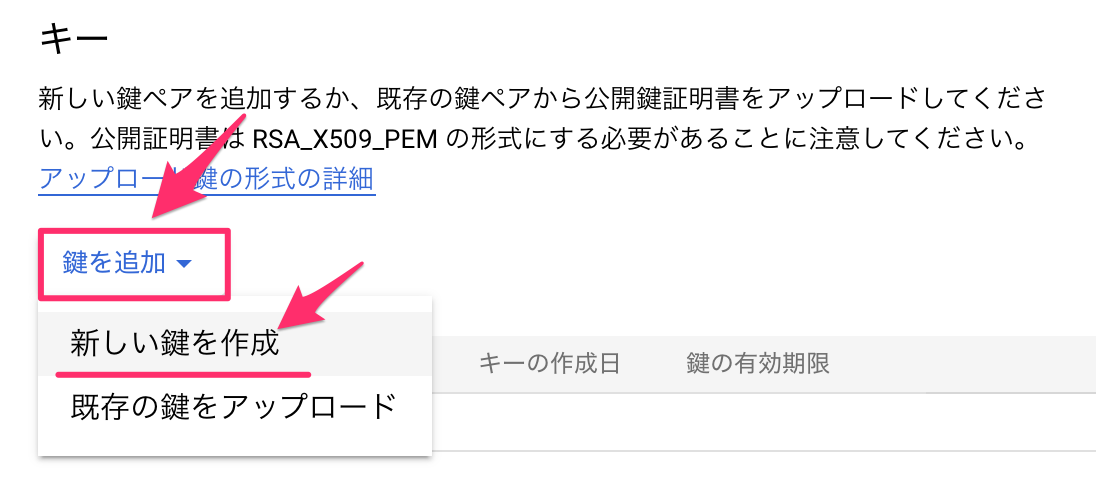
JSONを作成します。

ダウンロードしましょう。
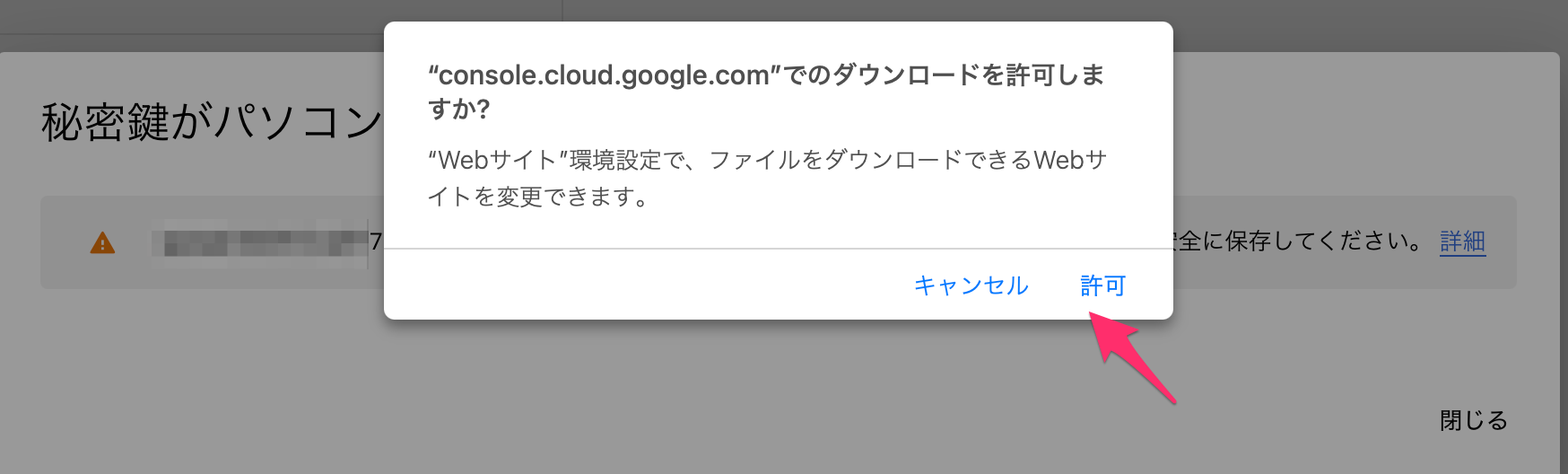
このJSONファイルはpythonのライブラリを使う場合に使用します。
APIキーの取得
APIキーはpythonだけでなく、ウェブのリクエストでOCR認識の結果を受け取るときに使います。
再度、認証情報のところに行きます。
次は、APIキーを選択します。

APIキーが発行されます。

このAPIキーを使うと、python以外でもウェブのリクエストを飛ばすことでOCR認識できます。
必要に応じて、右下のキー制限でアクセス制限をつけると良いでしょう。
方法その1 ウェブリクエスト
ウェブのリクエストの方法では、取得したAPIキーを使います。
特に、新しいライブラリのインストールが必要ということはありません。
API_KEY = ''に取得したAPIキーを入れます。
import requests
import base64
import json
API_KEY = ''
GOOGLE_CLOUD_VISION_API_URL = 'https://vision.googleapis.com/v1/images:annotate?key='
# TEXT_DETECTION:比較的短い文字
# DOCUMENT_TEXT_DETECTION:文章
DETECTION_TYPE = "DOCUMENT_TEXT_DETECTION"
def request_cloud_vison_api(image_base64, type="DOCUMENT_TEXT_DETECTION"):
""" http のリクエストでVisionAPIにアクセス """
api_url = GOOGLE_CLOUD_VISION_API_URL + API_KEY
req_body = json.dumps({
'requests': [{
'image': {
'content': image_base64.decode('utf-8')
},
'features': [{
'type': type,
'maxResults': 10,
}]
}]
})
res = requests.post(api_url, data=req_body)
return res.json()
def img_to_base64(filepath):
""" 画像データをエンコード """
with open(filepath, 'rb') as img:
img_byte = img.read()
return base64.b64encode(img_byte)
def render_doc_text(file_path):
result = request_cloud_vison_api(image_base64=img_to_base64(file_path),
type=DETECTION_TYPE)
data_list = []
# データの取得 textAnnotationsに座標とテキスト fullTextAnnotationにテキスト
result_list = result["responses"][0]["textAnnotations"]
for d in result_list:
data_list.append([d['boundingPoly']['vertices'], d['description']])
# 1つ目除外
data_list = data_list[1:len(data_list)]
return data_list
render_doc_text関数に画像ファイルを渡すことで、検出した文字と座標を取得します。
このコードを「google_ocr_api.py」として保存します。
方法その2 ライブラリ
次に、google-cloud-visionライブラリを使った方法です。
こちらでは、先ほどのJSONファイルを使います。
ライブラリのインストール
pipを使って、ライブラリをインストールしましょう
pip install google-cloud-vision
環境変数の設定
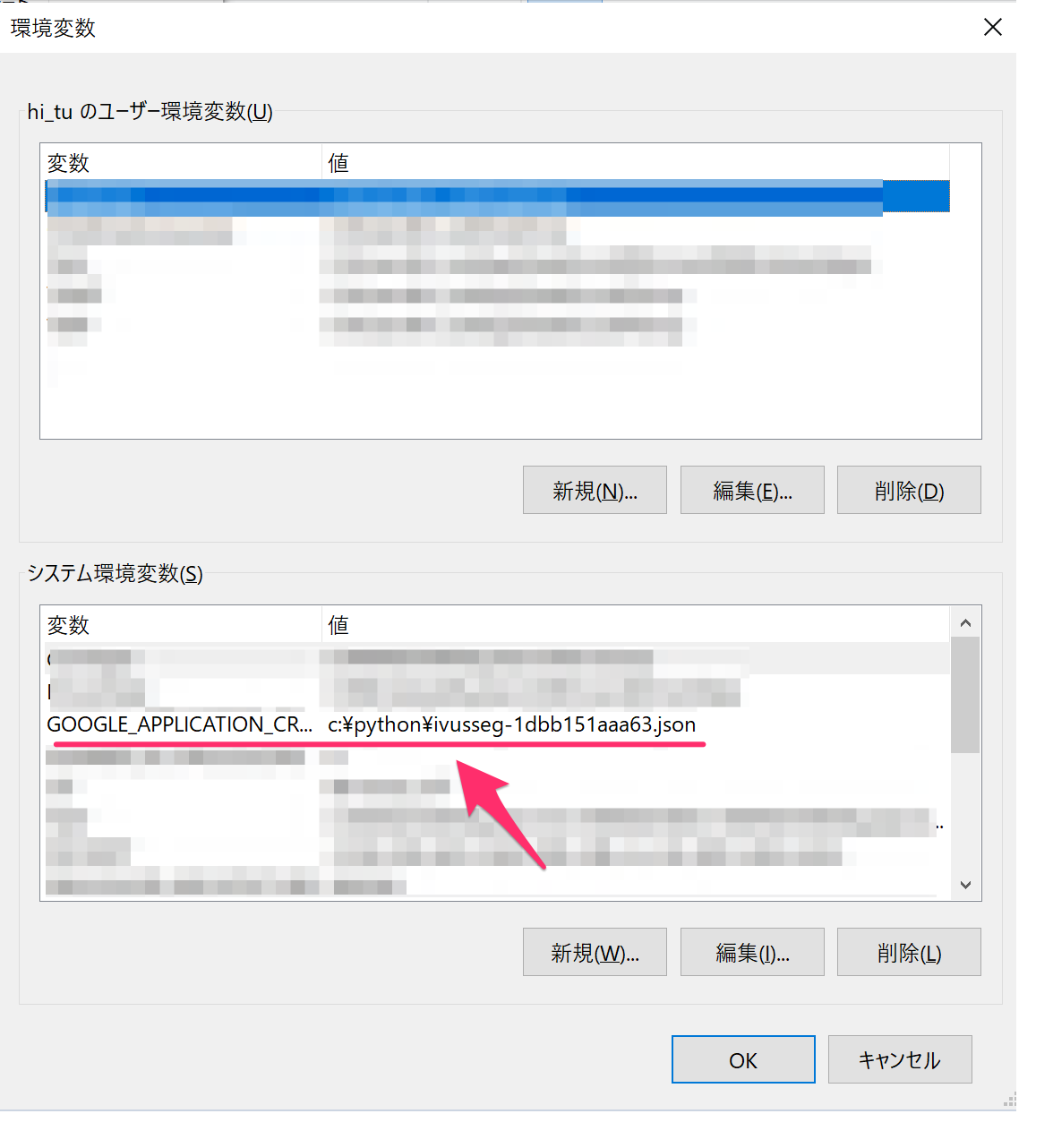
先ほど取得した、jsonファイルは環境変数に登録します。
UbuntuやMacの場合
export GOOGLE_APPLICATION_CREDENTIALS="jsonファイルパス"
Windowsの場合、コントロールパネル>システム>環境変数から設定しましょう。
設定が終われば、あとはコードです。
from pathlib import Path
from google.cloud import vision
def render_doc_text(filein):
client = vision.ImageAnnotatorClient()
p = Path(__file__).parent / filein
with p.open('rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
data_list = []
response = client.document_text_detection(image=image)
document = response.full_text_annotation
for page in document.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
box = [{'x':v.x, 'y':v.y} for v in word.bounding_box.vertices]
text = [symbol.text for symbol in word.symbols]
data_list.append([box, ''.join(text)])
return data_list
このrender_doc_text関数は、ウェブリクエストの時と同じデータを取得します。
ですので、どちらを使ってもOKです。
このコードを「google_ocr_lib.py」として保存します。
検出したデータの処理
ここからは、個人的にこういう処理するかなといったイメージになるので、参考にしていただけたらと思います。
紹介した各方法で、render_doc_text関数を使うと、検出した文字と検出した箇所が四角の座標で取得できます。
次のようなイメージです。
左が検出前、右が検出後です。
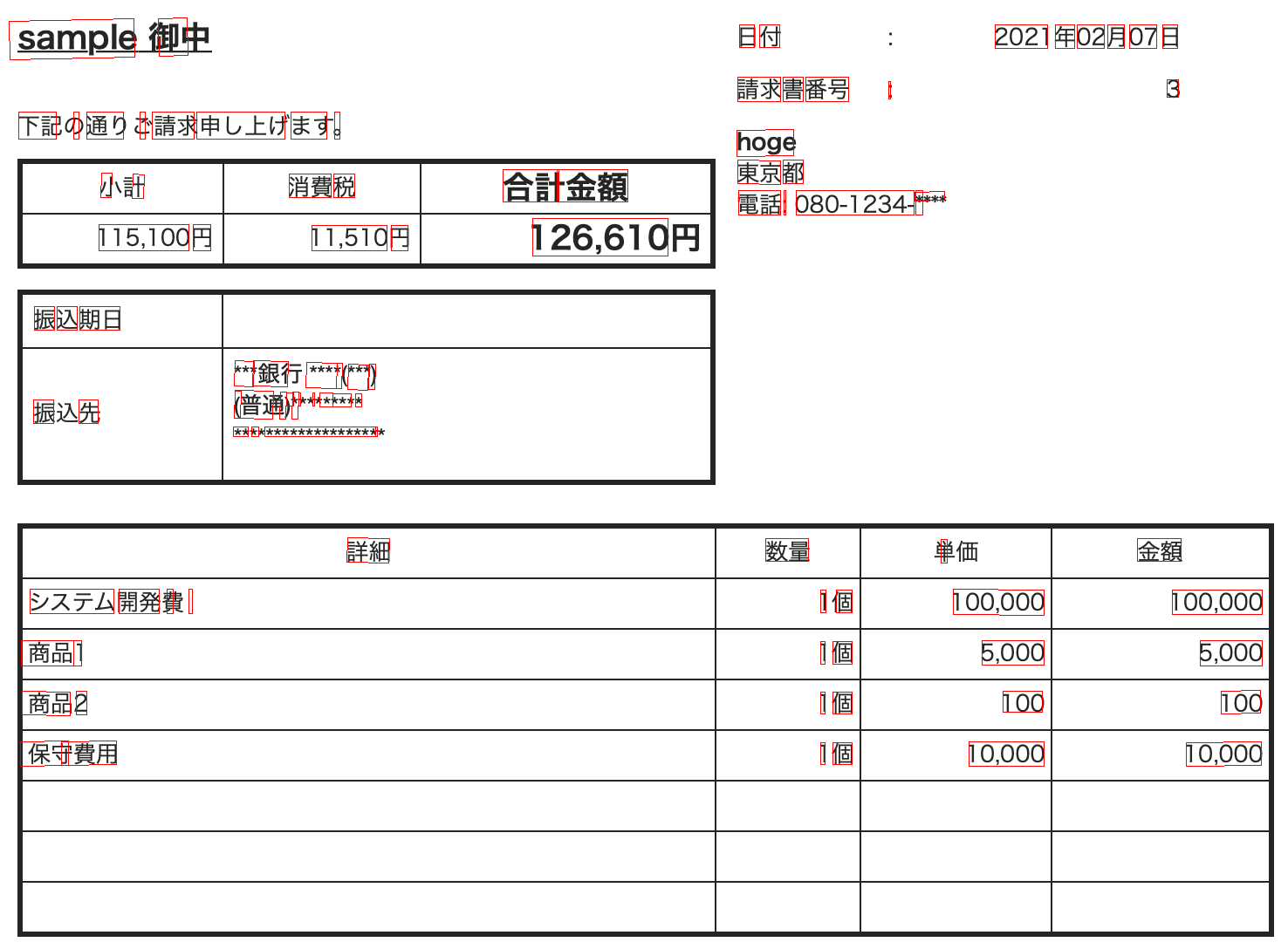
最終的に取得したいデータは、四角の各ポイントではなく、中心座標と文字とします。
これは個人的に処理しやすいと思ったからです。

課題点
検出した文字を見ると以下のような課題があります。
ポイント
文字の区切りがおかしい。例、商品1は「商品」「1」となっている
検出できない文字、検出文字が違う
2つ目は動かしてもらって、中身を見るとわかりますが、これはどうしようもないので、少なくとも1つ目は解決していきます。
サンプルコード
render_doc_textで取得したデータを最終的にx,y,文字のpandasのDataFrameにします。
いくつか関数を用意しています。
| 関数名 | 機能 |
| rect_to_point | 座標の中心を算出 |
| rect_ave_height_degree | 検出した四角の平均高さ、傾きを算出 高さは、文字が近接しているかの判断に使っています。 文字高さ分に近ければ、近接文字扱いするとかです。 傾きは画像の傾き補正に使おうと思いましたが、使っていません。 |
| join_nearest | 近接文字を結合します。 |
実際のコードを紹介します。
from google_ocr_lib import render_doc_text
# from google_ocr_api import render_doc_text
import numpy as np
import math
import pandas as pd
def rect_to_point(rect):
""" 文字rectの中心座標 """
x = []
y = []
for d in rect:
if 'x' in d:
x.append(d['x'])
if 'y' in d:
y.append(d['y'])
return sum(x)/len(x), sum(y)/len(y)
def rect_ave_height_degree(data_list):
""" 平均高さ、傾き """
height = []
degree = []
for rect in data_list:
x = []
y = []
for d in rect[0]:
if 'x' in d:
x.append(d['x'])
if 'y' in d:
y.append(d['y'])
# データ不足しているのは無視します。
if len(x)==4 and len(y)==4:
height.append(((y[3]-y[0])+(y[2]-y[1]))/2)
if (x[1]-x[0]) == 0:
tan = 0
else:
tan = (y[1] - y[0]) / (x[1] - x[0])
atan = np.arctan(tan) * 180 / math.pi
degree.append(atan)
# 平均値を返す。場合によっては中央値でもよい。
return sum(height)/len(height), sum(degree)/len(degree)
def join_nearest(data_list, height):
""" 近接の文字結合 """
ret_data = []
data_list.reverse()
# データなくなるまで
while data_list:
d = data_list.pop()
most_near = 0
# 近接文字なくなるまで
while most_near!=-1:
rect = d[0]
most_near = -1
if ('x' in rect[1]) and ('y' in rect[1]):
curent_x = rect[1]['x']
curent_y = rect[1]['y']
# 右に文字高さの 1/2 以内の近さがあれば
temp_data = data_list.copy()
for ind2, d2 in enumerate(temp_data):
rect2 = d2[0]
if ('x' in rect2[0]) and ('y' in rect2[0]):
other_x = rect2[0]['x']
other_y = rect2[0]['y']
# 距離の近いところ
if (abs(other_x-curent_x)<height/2) and (abs(other_y-curent_y)<height/2): most_near = ind2 break # 文字連結 if most_near>0:
# 連結
new_rect = []
new_rect.append(rect[0])
new_rect.append(rect2[1])
new_rect.append(rect2[2])
new_rect.append(rect[3])
new_str = d[1] + d2[1]
d = [new_rect, new_str]
# 連結したデータも削除
del data_list[ind2]
else:
ret_data.append(d)
break
return ret_data
if __name__ == '__main__':
# OCR検知
data_list = render_doc_text('sample.png')
# 高さ、角度
height, degree = rect_ave_height_degree(data_list)
# 近接文字結合
data_list = join_nearest(data_list, height)
# 中央座標に変換して、DataFrameに変更
new_data_list = []
for d in data_list:
x, y = rect_to_point(d[0])
new_data_list.append([x, y, d[1]])
df = pd.DataFrame(data=new_data_list, columns=['x', 'y', 'text'])
print(df)
このコードを「main.py」として、1,2行目でgoogle_ocr_libかgoogle_ocr_apiを読んでいます。
使いたいほうを使ってください。
実行すると、DataFrameにデータが入りますので、CSVにデータ保存したら、他にも処理を追加したりすると良いでしょう。
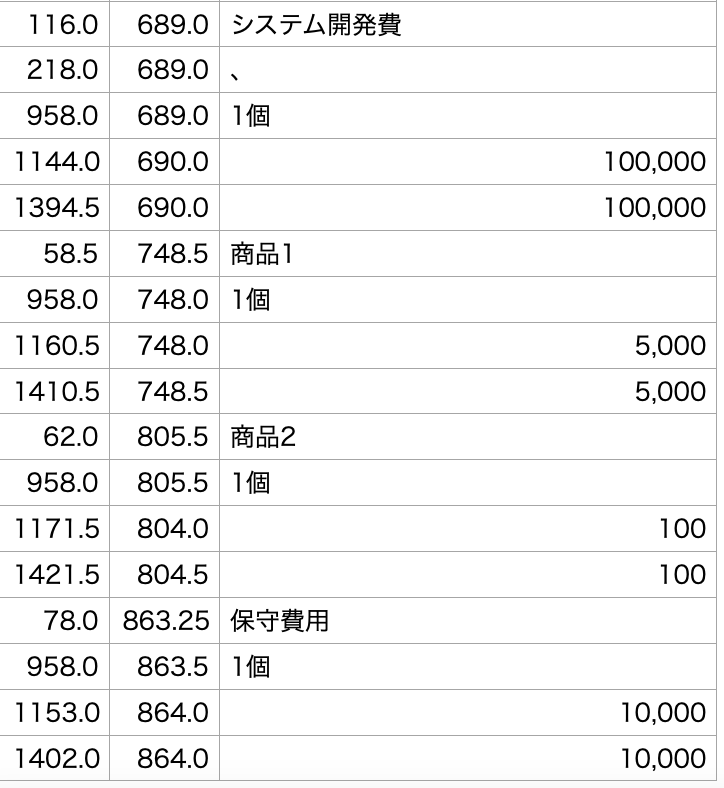
近接文字をするしないでは次のように差が出ます。
左が、何もしない状態、右が近接文字をつけた場合。
これは、データによっては役に立たないかもしれませんが、帳票の画像からデータを抜き取るときはこういった工夫がいるのではないでしょうか?

他の活用方法は「python 活用 できることまとめ」も参考にしてください。
Pythonスキルが身に付いたら、ぜひスキルを生かして稼いでいきましょう!