前回の赤ちゃん見守りAIのシステム構想をしたので、その続きです。
最初に、赤ちゃん検知AIを作成しようと思います。
検知は、体と顔。
体:特に使わなそうなのと、布団よく被っているので省略
顔:笑う、泣くなど表情検知用

目次
画像取得
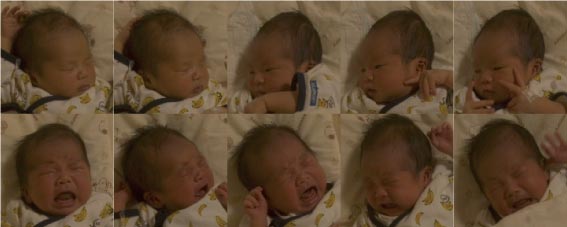
学習用の画像を集めるために、Jetsonとカメラをベビーベットに固定して、画像を収集。

ディスプレイで見るより、茶色っぽく保存されていますが、とりあえずこのままデータを集めます。
*追記:少し、ウェイトかけると茶色っぽくなくなりました。カメラに接続してすぐの画像が変な場合はウェイト入れてみてください。

使うAI
AIは2段階で分けます
- 顔と
体の位置を検出するもの - 顔の表情を検出するのもの
OpenCVとかで、顔検出はあると思いますが、好きな方、適した方を選ぶと良いのかと思います。
2段階に分けずに、位置検出時に、顔の表情の分類をするのも良いと思います。
位置検出の学習
概要
顔と体を検出しようと思っていましたが、特に体検出してそのデータを使うこともないので、
顔のみを検出します。
*下記の検出するのに使用した画像は100枚です。

顔の表情の学習
概要
顔の表情は、顔を検出して、切り取ってものを集めて学習する。
- 普通/寝る
- 泣く
- 笑う
笑う以外はすぐ集まりそうですね。笑うはおいおい。
泣いているのも、かわいそうなので、少しずつ。
顔部分切り取り方(クリッピング)
YOLOを動かすと、out_boxesという値が取得できるので、この値を使用します。
左上のy,x 右下のy,xを表しています。
print(out_boxes)
array([[ 34, 284, 172, 380]], dtype=int32)次にこの座標データでどのように切り取るかですが、
OpenCVで取得する画像は、[高さ,幅,RGB]の配列のデータになるので、
単純に、高さ、幅の範囲を指定して画像を保存します。
切り取る範囲は、144×144がちょうど良い大きさなので、このサイズとします。
以下サンプル、コードです。
Githubにあるファイルが必要になります。

### ライブラリ読みこみ
import cv2
import time
import threading
import datetime
import signal
import os
from ftplib import FTP
from PIL import Image, ImageFont, ImageDraw
import scipy.io
import scipy.misc
import numpy as np
import argparse
import pandas as pd
import tensorflow as tf
from keras import backend as K
from keras.layers import Input, Lambda, Conv2D
from keras.models import load_model, Model
from yolo_utils import read_classes, read_anchors, generate_colors, preprocess_image, draw_boxes, scale_boxes
from keras_yolo import yolo_head, preprocess_true_boxes, yolo_loss, yolo_body,yolo_eval,tiny_yolo_body
import glob
### YOLOの設定
sess = K.get_session()
image_size = 384
image_input = Input(shape=(image_size, image_size, 3))
dataname = 'face'
class_names = [dataname]
YOLO_ANCHORS = np.array(
((0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434),
(7.88282, 3.52778), (9.77052, 9.16828)))
anchors = YOLO_ANCHORS
yolo = tiny_yolo_body(image_input, len(anchors), len(class_names))
yolo.load_weights('tiny_weights.h5')
image_shape = (480., 640.)
yolo_outputs = yolo_head(yolo.output, anchors, len(class_names))
boxes, scores, classes = yolo_eval(yolo_outputs, image_shape)
### 切り取った画像があるフォルダをループ
fileList = glob.glob('images/*')
for filename in fileList:
## 画像読み込みと位置検出
img = cv2.imread(filename)
imgPil = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
imgPil = Image.fromarray(imgPil)
resized_image = imgPil.resize(tuple(reversed((384, 384))), Image.BICUBIC)
image_data = np.array(resized_image, dtype='float32')
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_scores, out_boxes, out_classes = sess.run([scores, boxes, classes], feed_dict={yolo.input: image_data, K.learning_phase(): 0})
print('Found {} boxes for {}'.format(len(out_boxes), "hoge"))
# Generate colors for drawing bounding boxes.
colors = generate_colors(class_names)
# Draw bounding boxes on the image file
draw_boxes(imgPil, out_scores, out_boxes, out_classes, class_names, colors)
##144でクリップ
out_boxes = out_boxes.astype(np.int32)
#検出のセンター座標
cx = 0
cy = 0
#クリッピングする座標
clipbox = np.zeros([1,4],dtype=np.int32)
#顔検出できた場合
if len(out_boxes) > 0:
cx = round((out_boxes[0][3] - out_boxes[0][1]) / 2 + out_boxes[0][1])
cy = round((out_boxes[0][2] - out_boxes[0][0]) / 2 + out_boxes[0][0])
if cx > 72:
clipbox[0][1] = cx - 72
clipbox[0][3] = cx + 72
else:
clipbox[0][1] = 0
clipbox[0][3] = 144
if cy > 72:
clipbox[0][0] = cy - 72
clipbox[0][2] = cy + 72
else:
clipbox[0][0] = 0
clipbox[0][2] = 144
filename = "cliped/%s" % os.path.basename(filename)
cv2.imwrite(filename, img[clipbox[0][0]:clipbox[0][2],
clipbox[0][1]:clipbox[0][3],
:])AIの作り方
画像の分類は下記記事で使っているものを使います。
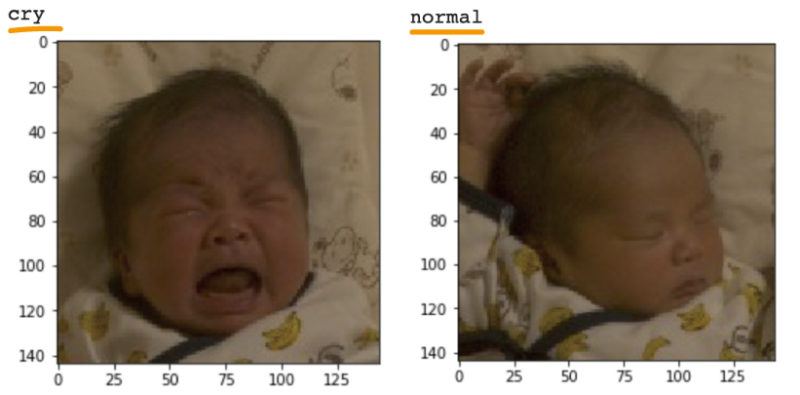
切り取った赤ちゃんの顔の画像をcry、normal、laughなどのフォルダに分けて、
分類できるAIを作ります。
ちゃんと分類できてます。
今後、寝てる、起きてるとかもちゃんと分けていきたいと思います。
モデルの保存
前述の記事ではAIモデルの保存をしていません。
Jetson nanoで動かすには、モデルの保存が必要なので、下記コードで保存します。
ファイル名はなんでも良いです。
model.save('/content/drive/My Drive/Colab Notebooks/babybot/face_reco.h5')学習の精度UP応用
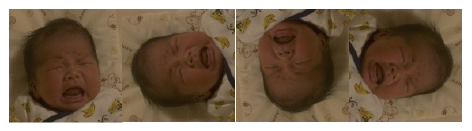
データ数が少ない時に使われる手法です。
顔のデータは144×144のサイズにしているのと、顔の向きはどの向きでも考えられます。
ですので、1つの切り取った顔のデータを読み込む時に、画像を回転させたものも1つのデータとして読み込みます。そうすることで、より精度が上がります。
Jetson Nano 実装
JetsonNanoにはピーマン位置検知の時に使ったものをベースに、以下を追加しています。
- 検知した顔を切り取り
- 顔の表情の分類
- FTPでxserverに転送(後でLINEで写真共有のためのサンプルコード)
コードは下記になります。
画像は一枚のみ取得して、AIで判別させています。
画像一枚でなく、ループすることで、動画でリアルタイムに検知もできると思います。
import cv2
import time
import threading
import datetime
import signal
import os
from ftplib import FTP
from PIL import Image, ImageFont, ImageDraw
import scipy.io
import scipy.misc
import numpy as np
import argparse
import pandas as pd
import tensorflow as tf
from keras import backend as K
from keras.layers import Input, Lambda, Conv2D
from tensorflow.keras.models import load_model, Model
from yolo_utils import read_classes, read_anchors, generate_colors, preprocess_image, draw_boxes, scale_boxes
from keras_yolo import yolo_head, preprocess_true_boxes, yolo_loss, yolo_body,yolo_eval,tiny_yolo_body
GST_STR = 'nvarguscamerasrc \
! video/x-raw(memory:NVMM), width=3280, height=2464, format=(string)NV12, framerate=(fraction)30/1 \
! nvvidconv ! video/x-raw, width=(int)640, height=(int)480, format=(string)BGRx \
! videoconvert \
! appsink'
WINDOW_NAME = 'Camera Test'
def captureImage():
### load face recognition model ###
#face_reco.h5は顔の表情の分類時のモデルとパラメータのデータ
fc_model = load_model('face_reco.h5')
ClassName = ['normal','cry']
### Setting YOLO ###
sess = K.get_session()
image_size = 384
image_input = Input(shape=(image_size, image_size, 3))
dataname = 'face'
class_names = [dataname]
YOLO_ANCHORS = np.array(
((0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434),
(7.88282, 3.52778), (9.77052, 9.16828)))
anchors = YOLO_ANCHORS
yolo = tiny_yolo_body(image_input, len(anchors), len(class_names))
yolo.load_weights('tiny_weights.h5')
image_shape = (480., 640.)
yolo_outputs = yolo_head(yolo.output, anchors, len(class_names))
boxes, scores, classes = yolo_eval(yolo_outputs, image_shape)
ftp = FTP(
host = "***",
user = "***",
passwd="***"
)
### get image ###
cap = cv2.VideoCapture(GST_STR, cv2.CAP_GSTREAMER)
now = datetime.datetime.now()
ret, img = cap.read()
imgPil = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
imgPil = Image.fromarray(imgPil)
resized_image = imgPil.resize(tuple(reversed((384, 384))), Image.BICUBIC)
image_data = np.array(resized_image, dtype='float32')
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
### YOLO ###
out_scores, out_boxes, out_classes = sess.run([scores, boxes, classes], feed_dict={yolo.input: image_data, K.learning_phase(): 0})
print('Found {} boxes for {}'.format(len(out_boxes), "hoge"))
# Generate colors for drawing bounding boxes.
#colors = generate_colors(class_names)
# Draw bounding boxes on the image file
#draw_boxes(imgPil, out_scores, out_boxes, out_classes, class_names, colors)
filename = "images/%s.jpg" % now.strftime('%Y%m%d%H%M%S')
print(filename)
cv2.imwrite(filename, img)
#cv2.imwrite(filename, np.asarray(imgPil)[..., ::-1])
### baby face recognition 144でクリップ ###
out_boxes = out_boxes.astype(np.int32)
#検出のセンター座標
cx = 0
cy = 0
#クリッピングする座標
clipbox = np.zeros([1,4],dtype=np.int32)
#顔検出できた場合
if len(out_boxes) > 0:
cx = round((out_boxes[0][3] - out_boxes[0][1]) / 2 + out_boxes[0][1])
cy = round((out_boxes[0][2] - out_boxes[0][0]) / 2 + out_boxes[0][0])
if cx > 72:
clipbox[0][1] = cx - 72
clipbox[0][3] = cx + 72
else:
clipbox[0][1] = 0
clipbox[0][3] = 144
if cy > 72:
clipbox[0][0] = cy - 72
clipbox[0][2] = cy + 72
else:
clipbox[0][0] = 0
clipbox[0][2] = 144
imgclip = img[clipbox[0][0]:clipbox[0][2],clipbox[0][1]:clipbox[0][3],:] / 255.0
#print(imgclip.shape)
imgclip = np.array([cv2.resize(imgclip, (256, 256))])
#print(imgclip.shape)
predicted = fc_model.predict(imgclip)[0]
print(ClassName[np.argmax(predicted)])
### FTP to xserver
with open(filename, "rb") as f:
ftp.storbinary(("STOR latest_%s.jpg" % ClassName[np.argmax(predicted)]), f)
with open(filename, "rb") as f:
ftp.storbinary("STOR latest.jpg", f)
ftp.quit()
cap.release()
def main():
captureImage()
if __name__ == "__main__":
main()
最後に
これでざっくりですが、赤ちゃんの状態をAIで検知することができるようになりました。
まだ、画像が足りないのと、赤ちゃんの成長に合わせて都度学習させる予定です。
ボーン検知とかでポーズの種類とか色々遊んでみるのも良さそう。
次は、Jetson nanoで泣いているよ!とかいう風に見守っている結果を、LINEで共有できるようにしたいと思います。
細かく、説明できてない部分もあるので、興味があれば気軽に問い合わせください。